时间:2024-10-17 16:49
人气:
作者:admin
OpenAI新模型o1号称编程能力8倍杀GPT-4o,MMLU媲美人类专家,MMLU是什么?评估大模型的标准是什么?
相信大家在阅读大模型相关文档的时候经常会看到MMLU,BBH,GSM8K,MATH,HumanEval,MBPP,C-Eval,CMMLU等等这些都是什么?大模型训练完成后,如何客观地评估其效果呢?
当然我们不能依靠主观判断,于是研究者们制定了一系列标准,用于测评大模型在不同数据集上的表现。而这些数据集( MMLU、C-Eval、GSM8K、MATH、HumanEval、MBPP、BBH 和 CMMLU),正是用于评估大模型性能的重要依据。

当然,它们也也可用于模型训练。
MMLU这个基准包含STEM(科学、技术、工程、数学)、人文学科、社会学科等57个学科领域,难度从初级到高级不等。

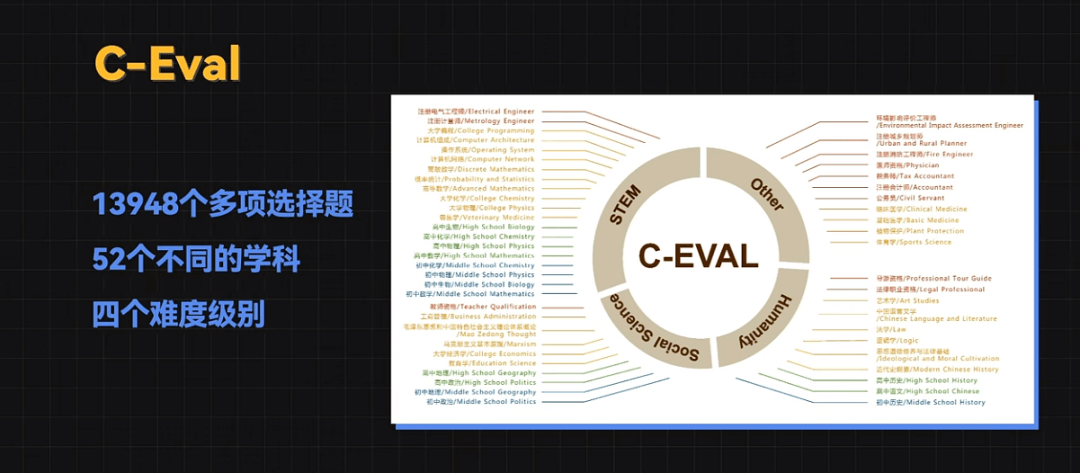
C-Eval 是一个全面的中文基础模型评估套件,它包含了13948个多项选择题,涵盖了52个不同的学科和四个难度级别。
GSM8K(Grade School Math)是一个由OpenAI发布的数据集,有8.5K个高质量语言多样的小学数学问题组成。这些问题需要 2 到 8 个步骤来解决,解决方法主要是使用基本的算术运算(+ - / *)进行一连串的基本计算,以得出最终答案。

虽然看起来很简单,但很多大模型的表现都不太好。
MATH是一个包含 12500 个数学竞赛问题的数据集,其中的每个问题都有一个完整的推导过程。

HumanEval是由 164 个简单编程问题组成,主要用来评估语言理解、算法和简单的数学。

MBPP(Mostly Basic Python Programming)由大约 1000 个Python 编程问题组成,每个问题由任务描述、代码解决方案和 3 个自动化测试用例组成。

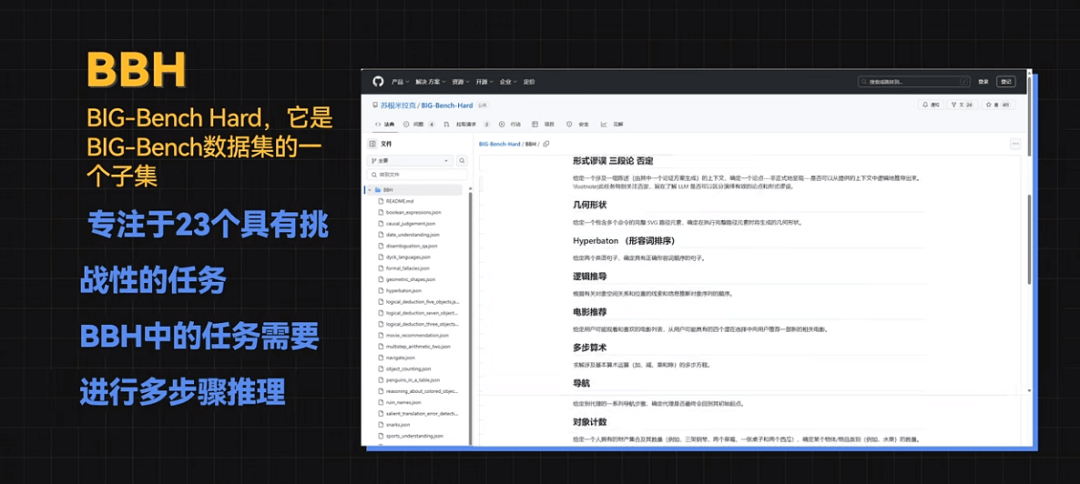
BBH的全称是BIG-Bench Hard,它是BIG-Bench数据集的一个子集,它专注于23个具有挑战性的任务,这些任务超出了当前语言模型的能力范围,BBH中的任务需要进行多步骤推理。
CMMLU,一个全面的中文大模型评估数据集。它涵盖了67个主题,涉及自然科学、社会科学、工程、人文、以及常识等,就是中文版的MMLU。

通过这些评测数据集和评估标准,我们可以从不同角度系统地评估大模型的性能、泛化能力和鲁棒性,为大模型的进一步研究和应用提供科学依据。
AI体系化学习路线
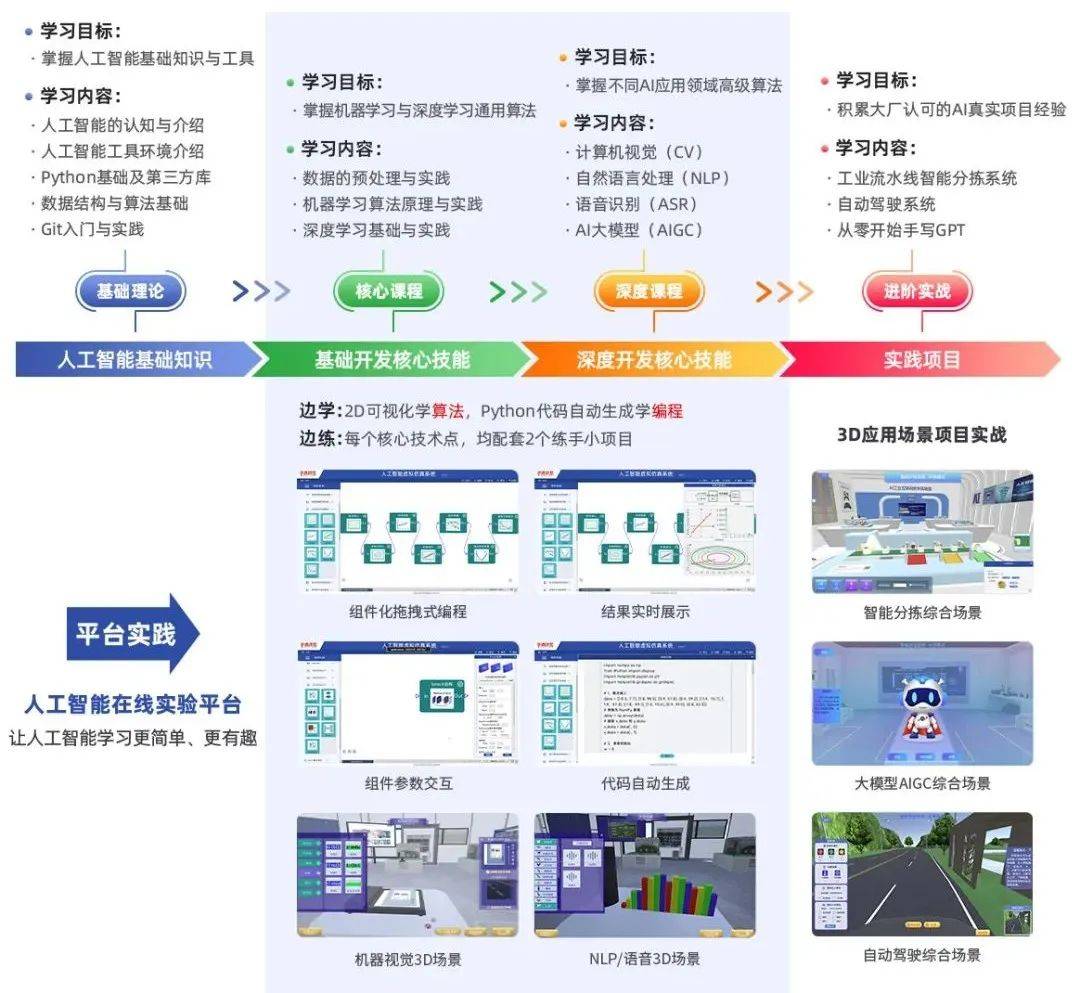
学习资料免费领
• AI全体系学习路线超详版
• AI体验卡(AI实验平台体验权限)
• 100余讲AI视频课程
• 项目源码《从零开始训练与部署YOLOV8》
• 170余篇AI经典论文
全体系课程详情介绍






 关注微信
关注微信