时间:2024-03-25 13:57
人气:
作者:admin
如今,人工智能 (AI) 无处不在,从互联网核心的数据中心到互联网边缘的传感器和手持设备(如智能手机)以及介于两者之间的每个点,例如自主机器人和车辆。
人工智能有两个主要方面:训练,主要在数据中心进行,以及推理,可以在从云到最不起眼的人工智能传感器的任何地方进行。
人工智能贪婪地消耗了两样东西:计算处理能力和数据。在处理能力方面,ChatGPT 的创建者 OpenAI 发布了报告,显示自 2012 年以来,大型 AI 训练运行中使用的计算量每 3.4 个月翻一番,而且没有放缓的迹象。
在内存方面,像 ChatGPT-4 这样的大型生成式 AI (GenAI) 模型可能有超过一万亿个参数,所有这些参数都需要以一种允许同时处理大量请求的方式访问。此外,还需要考虑需要流式传输和处理的大量数据。
速度慢的方案
假设我们正在设计一个包含一个或多个处理器内核的片上系统 (SoC) 设备。我们将在设备内部包含相对少量的内存,而大部分内存将驻留在 SoC 外部的设备中。
最快的存储器类型是SRAM,但每个SRAM单元需要六个晶体管,因此SRAM在SoC内部很少使用,因为它会消耗大量的空间和功率。相比之下,DRAM每个单元只需要一个晶体管和电容器,这意味着它消耗的空间和功率要少得多。因此,DRAM 用于在 SoC 外部创建大容量存储设备。尽管DRAM提供高容量,但它比SRAM慢得多。
随着用于开发集成电路的工艺技术不断发展,结构越来越小,大多数设备变得越来越快。可悲的是,作为DRAM核心的晶体管-电容器位单元并非如此。事实上,由于其模拟性质,比特单元的速度几十年来基本保持不变。
话虽如此,从外部接口可以看出,DRAM的速度随着每一代产品的发展而翻了一番。由于每次内部访问都相对较慢,因此实现此目的的方式是在设备内部执行一系列burst访问。如果我们假设我们正在读取一系列连续的数据单词,那么接收第一个单词将需要相对较长的时间,但我们会更快地看到任何后续单词。
如果我们希望流式传输大块连续数据,这很有效,因为我们在传输开始时会受到一次性点击,之后后续访问会高速进行。但是,如果我们希望对较小的数据块执行多次访问,则会出现问题。
速度更快的方案
解决方案是使用高速SRAM在处理设备内部创建本地cache存储。当处理器首次从 DRAM 请求数据时,该数据的副本将存储在处理器的cache中。如果处理器随后希望重新访问相同的数据,它将使用其本地副本,该副本的访问速度要快得多。
在 SoC 内部使用多级cache是很常见的。这些称为 1 级 (L1)、2 级 (L2) 和 3 级 (L3)。第一个cache级别具有最小的容量,但访问速度最高,每个后续级别的容量更高,访问速度更低。如图 1 所示,假设系统时钟为 1GHz,DDR4 DRAM,处理器访问其 L1 cache仅需 1.8 ns,访问 L2 cache只需 6.4 ns,访问 L3 cache只需 26 ns。从外部 DRAM 访问一系列数据字中的第一个需要高达 70 ns。

图1 cache和 DRAM 访问速度
cache在 AI 中的作用
AI 的实现和部署方案种类繁多。就我们的 SoC 而言,一种可能性是创建一个或多个 AI 加速器 IP,每个 IP 都包含自己的内部cache。假设我们希望与 SoC 处理器集群保持cache coherence,我们可以将其视为保持数据的所有副本相同。然后,我们将不得不使用coherent interconnect形式的硬件cache coherence解决方案,例如 AMBA 规范中定义的 CHI。
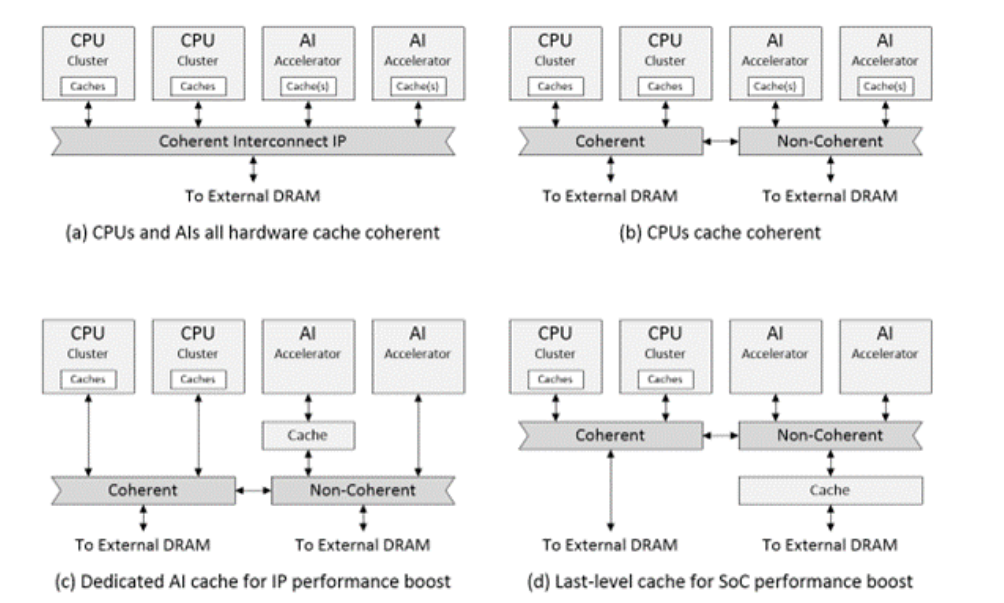
图2 cache示例。
维护cache一致性会产生开销。在许多情况下,AI 加速器不需要保持cache一致性,达到与处理器集群相同的程度。例如,可能只有在加速器处理了大量数据后,才需要重新同步,这可以在软件控制下实现。AI 加速器可以采用更小、更快的互连解决方案(图 2b)。
在许多情况下,加速器 IP 的开发人员在其实现中不包括cache。有时,在性能评估开始之前,没有认识到对cache的需求。一种解决方案是在 AI 加速器和互连之间加入一个特殊的cache IP,以提供 IP 级性能提升(图 2c)。另一种可能性是将cache IP 用作最后一级cache,以提供 SoC 级性能提升(图 2d)。
cache设计并不容易,但设计人员可以使用可配置的现成解决方案。
许多 SoC 设计人员倾向于只在处理器和处理器集群的上下文中考虑cache。但是,cache的优势同样适用于许多其他复杂 IP,包括 AI 加速器。因此,以 AI 为中心的 SoC 的开发人员越来越多地评估和部署各种支持cache的 AI 场景。
审核编辑:黄飞





 关注微信
关注微信