时间:2017-12-11 12:22
人气:
作者:admin
IBM研究院与瑞士洛桑联邦理工学院共同于2017 NIPS Conference发表大数据机器学习解决方案,此方法可以利用GPU在一分钟内处理完30GB的训练数据集,是现存有限内存训练方法的10倍。
研究团队表示,机器训练在大数据时代遇到的挑战是动辄TB等级起跳的训练数据,这是常见却又棘手的问题,或许一台有足够内存容量的服务器,就能将所有训练数据都加载内存中进行运算,但是仍要花费数小时,甚至是数周。
他们认为,目前如GPU等特殊的运算硬件,的确能有效加速运算,但仅限于运算密集的工作,而非数据密集的任务。 如果想要善用GPU运算密集的优势,便需要把数据预先加载到GPU内存,而目前GPU内存的容量最多只有16GB,对于机器学习实作来说并不算宽裕。
批次作业看似是一个可行的方法,将训练数据切分成一块一块,并且依造顺序加载至GPU做模型训练,不过经实验发现,从CPU将数据搬移进GPU的传输成本,完全盖过将数据放进GPU高速运算所带来的好处。 ,IBM研究员Celestine Dünner表示,在GPU做机器学习最大的挑战,就是不能把所有的数据都丢进内存里面。
为了解决这样的问题,研究团队开发为训练数据集标记重要性的技术,因此训练只使用重要的数据,那多数不必要的数据就不需要送进GPU,藉此大大节省训练的时间。 像是要训练分辨狗与猫图片的模型,一旦模型发现猫跟狗的差异之一为猫耳必定比狗小,系统将保留这项特征,在往后的训练模型中都不再重复回顾这个特征,因此模型的训练会越来越快。 IBM研究员Thomas Parnell表示,这样的特性便于更频繁的训练模型,也能更及时的调整模型。
这个技术是用来衡量每个数据点对学习算法的贡献有多少,主要利用二元差距的概念并及时影响调整训练算法。 将这个方法实际应用,研究团队在异质平台(Heterogeneous compute platforms)上,为机器学习训练模型开发了一个全新可重复使用的组件DuHL,专为二元差距的异质学习之用。
IBM表示,他们的下一个目标是在云端上提供DuHL,因为目前云端GPU服务的计费单位是小时,如果训练模型的时间从十小时缩短为一小时,那成本节省将非常惊人。
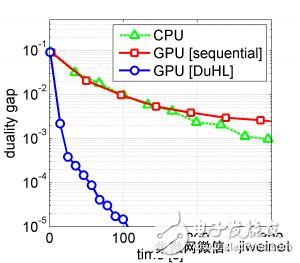
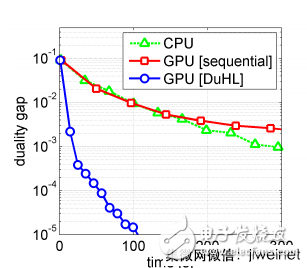
(上图)图中显示了三种算法所需的时间,包含DuHL在大规模的支持向量机的表现,所使用的数据集都为30GB的ImageNet数据库,硬件为内存8GB的NVIDIA Quadro M4000 GPU, 图中可以发现GPU序列批次的效率,甚至比单纯CPU的方法还要糟,而DuHL的速度为其他两种方法的10倍以上。
上一篇:事务深度遍历过程详解





 关注微信
关注微信