时间:2025-05-03 13:40
人气:
作者:admin

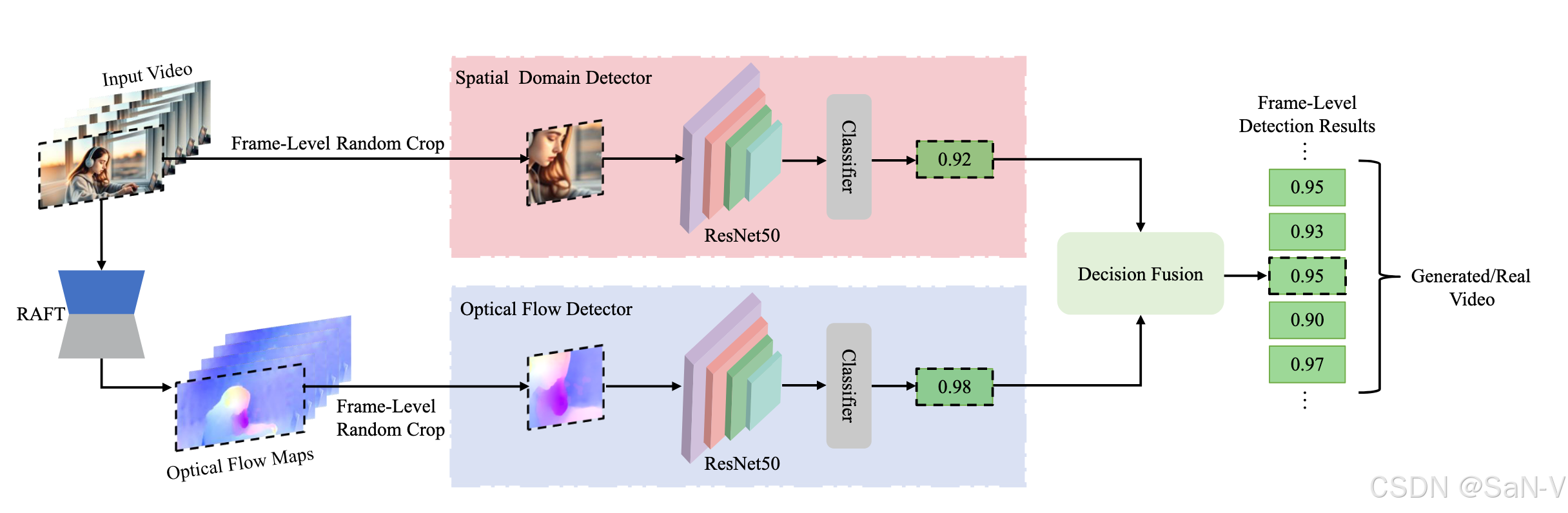
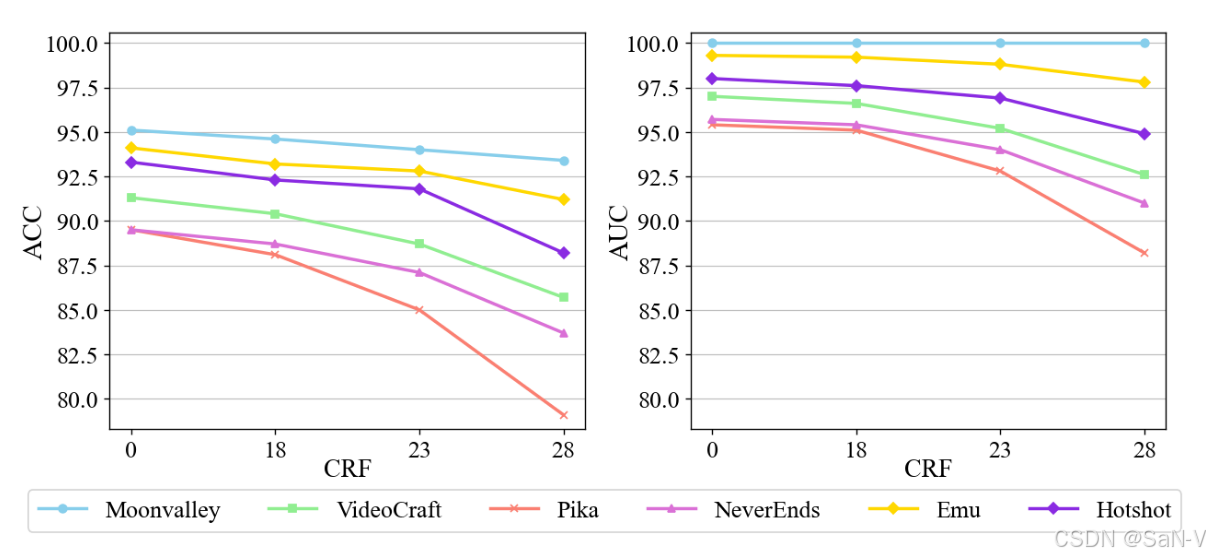
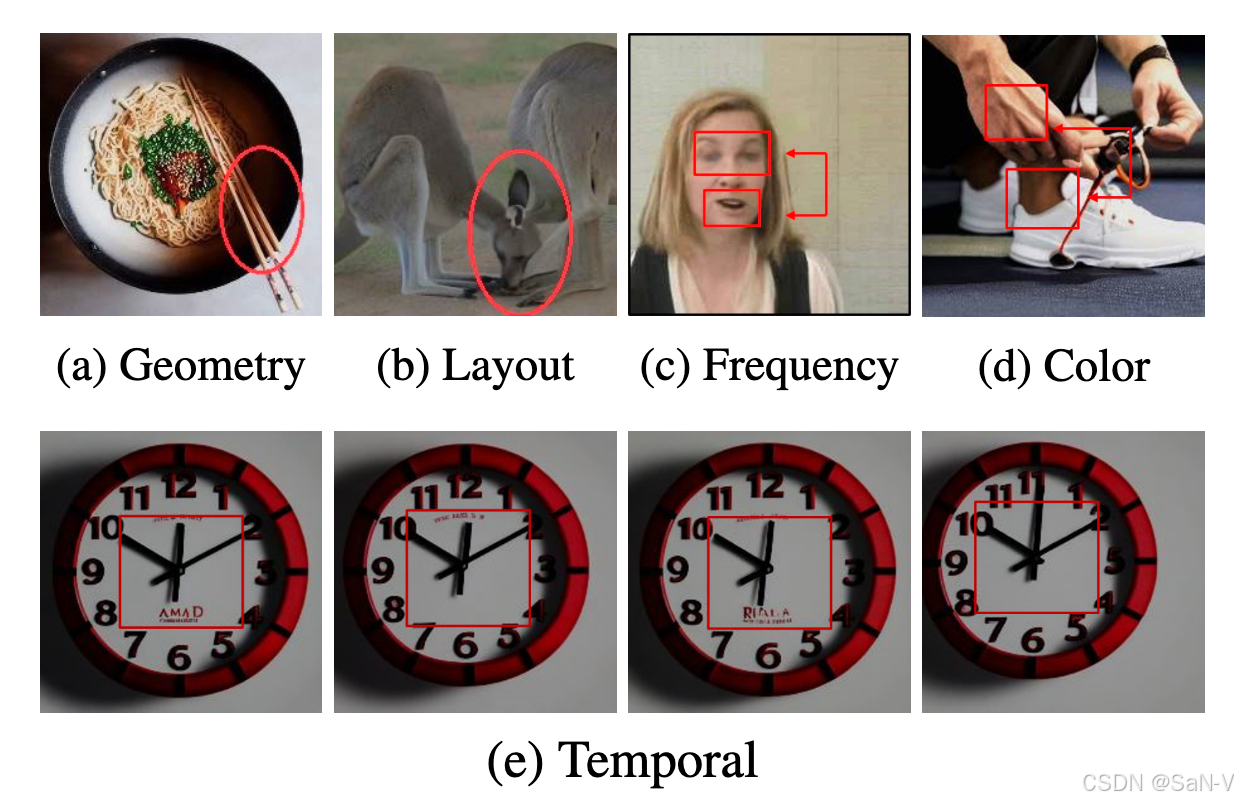

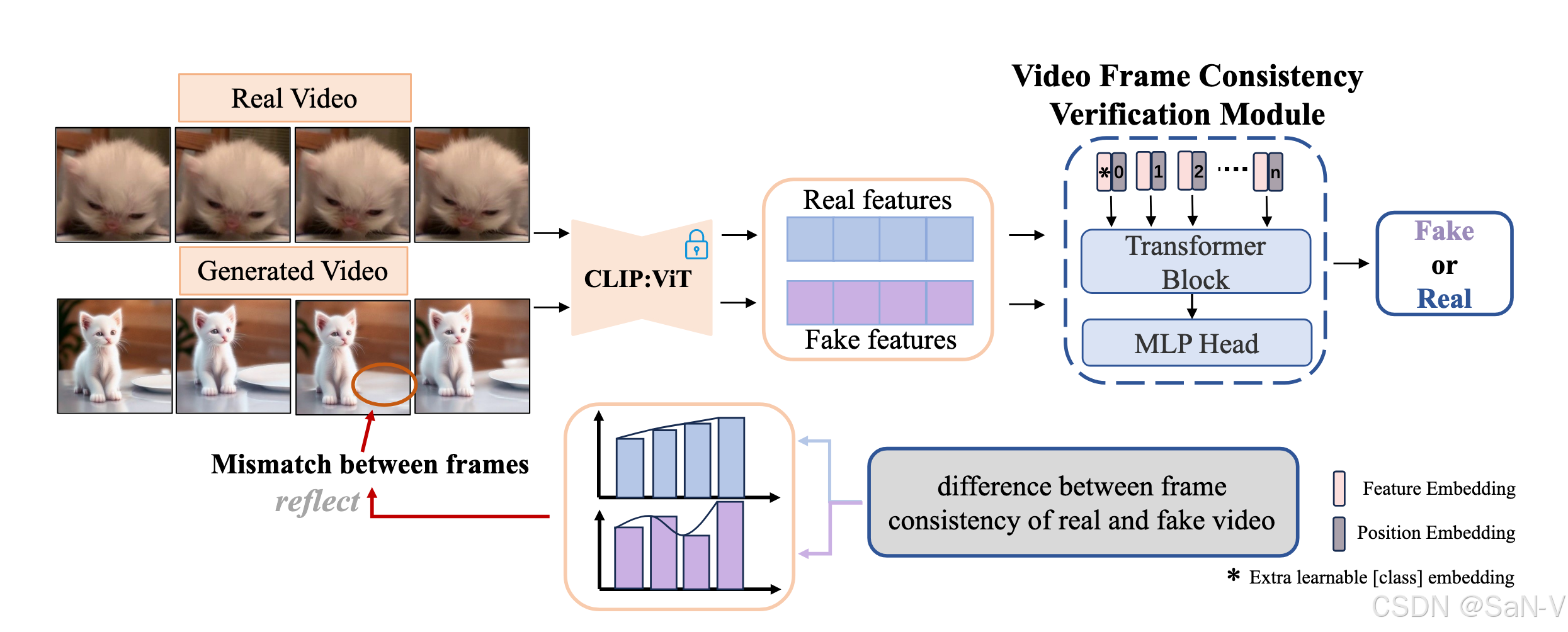
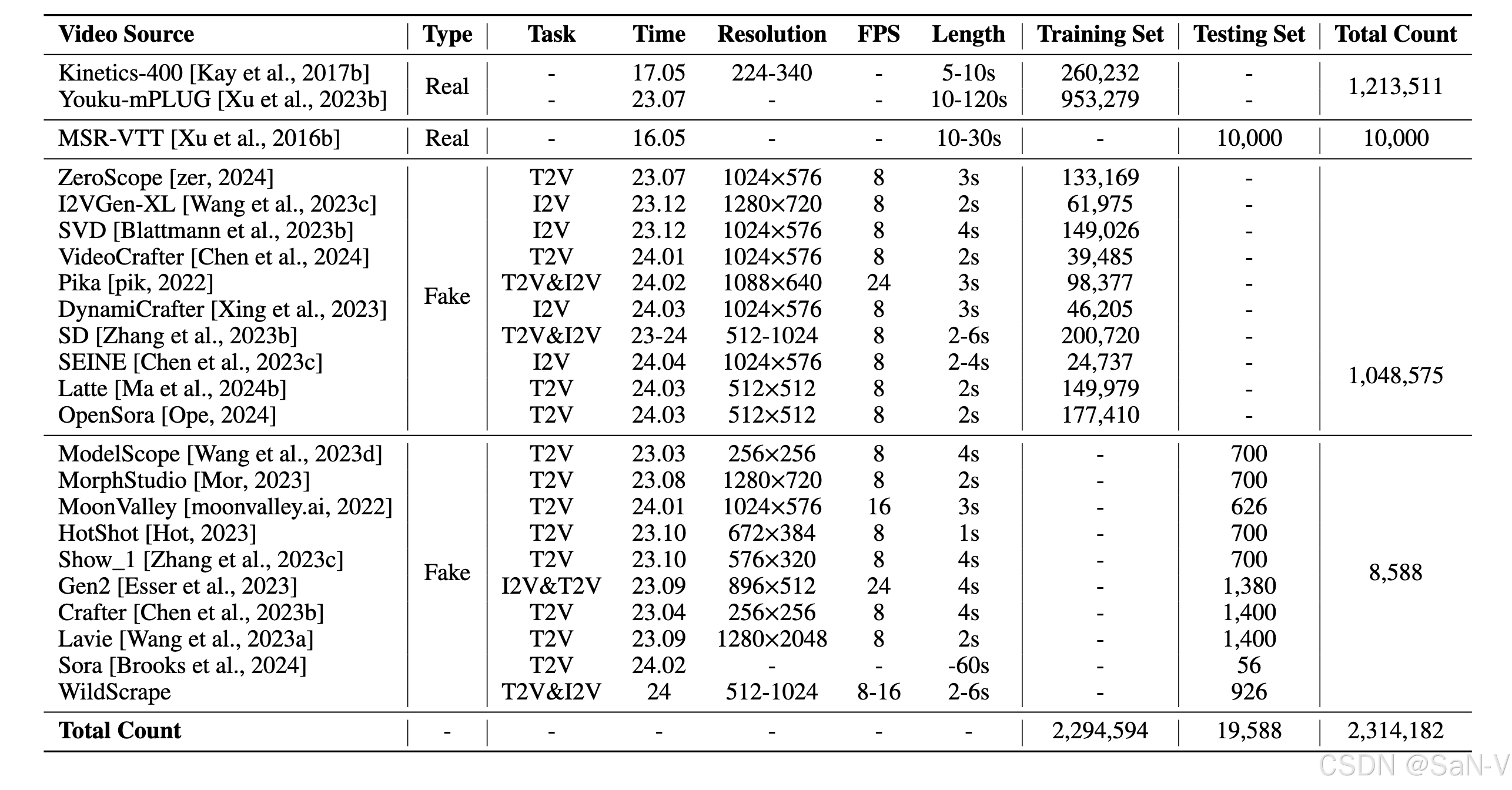

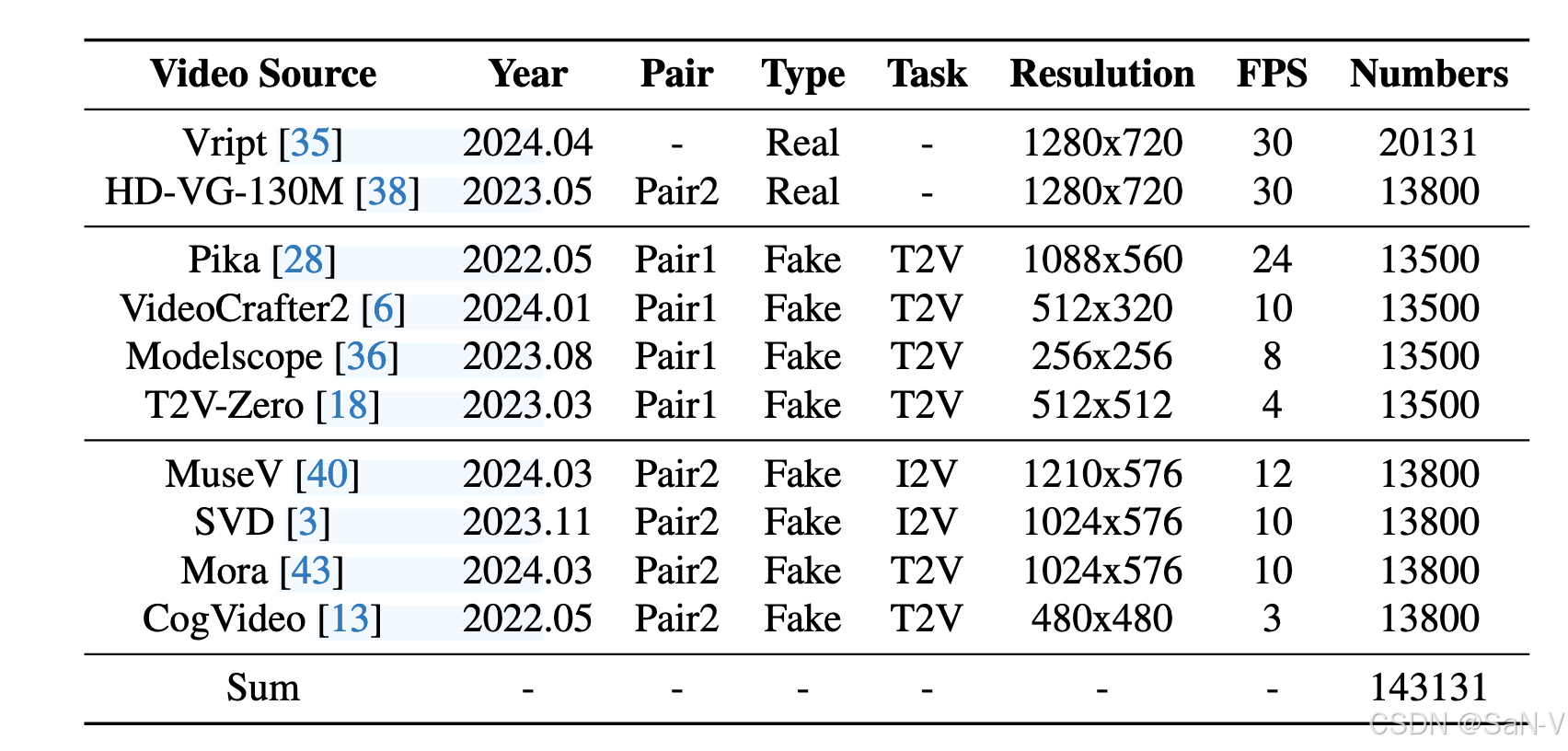
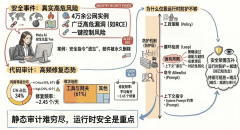
上表是GenVidBench 数据集中真实与生成视频的统计信息。GenVidBench 包含由8种先进生成器生成的8个伪造视频子集以及2个真实视频子集。视频对是根据生成来源(如文本提示或图像)进行划分的。

GVD 和 GenVideo 是之前的两个重要数据集,但它们有一些局限性,比如缺乏原始的生成提示、图像、视频对、语义标签和跨来源设置。这意味着这些数据集在训练集和测试集内容相似时,无法有效区分不同场景的问题。
GVF 尝试解决这些问题,提供了提示、图像、视频对和语义标签,但由于数据集规模较小(仅2.8k个视频),它仍然面临规模不足的问题。同时,它也没有跨来源设置,这使得它在多样性和挑战性方面有所欠缺。
GenVidBench 是一种改进的数据集,规模达到100,000个视频,涵盖了语义标签和用于生成视频的提示/图像,并进行了跨来源设置,从而使其在假视频检测方面更具挑战性。
“跨来源设置”(Cross-source setting)指的是在数据集的训练集和测试集中,使用来自不同来源(例如,不同的视频生成模型、不同的输入数据或不同的生成环境)的数据。这种设置的目的是增加数据的多样性,并减少模型在训练时可能学习到的偏差,使其能够更好地适应不同来源的视频生成,从而提高检测器的泛化能力。简单来说,跨来源设置增加了数据集的多样性和复杂性,是一种为了提升AI生成视频检测器性能而采用的策略。
“视频对”(Video pairs)指的是一对相关的两段视频,通常用于比较和分析。在生成视频检测的上下文中,视频对通常由以下两种类型组成:
真实视频与生成视频对:一个视频来自真实世界,而另一个视频则是由AI生成模型生成的。这对视频可以用来进行真假视频的对比,帮助检测器识别和区分AI生成的视频和真实视频。
相同提示的生成视频对:对于生成视频,可能会使用相同的输入提示或条件生成不同的视频。这种情况下,视频对中的两个视频来自相同的生成模型,但它们是基于相同的输入生成的,可以用来分析不同生成模型或不同生成参数下,AI生成的视频之间的差异。
在检测任务中,视频对的使用有助于训练模型识别两个视频之间的异同,特别是在对比真假视频时,可以通过直接比较它们的内容、特征、风格等来提高检测的精度。
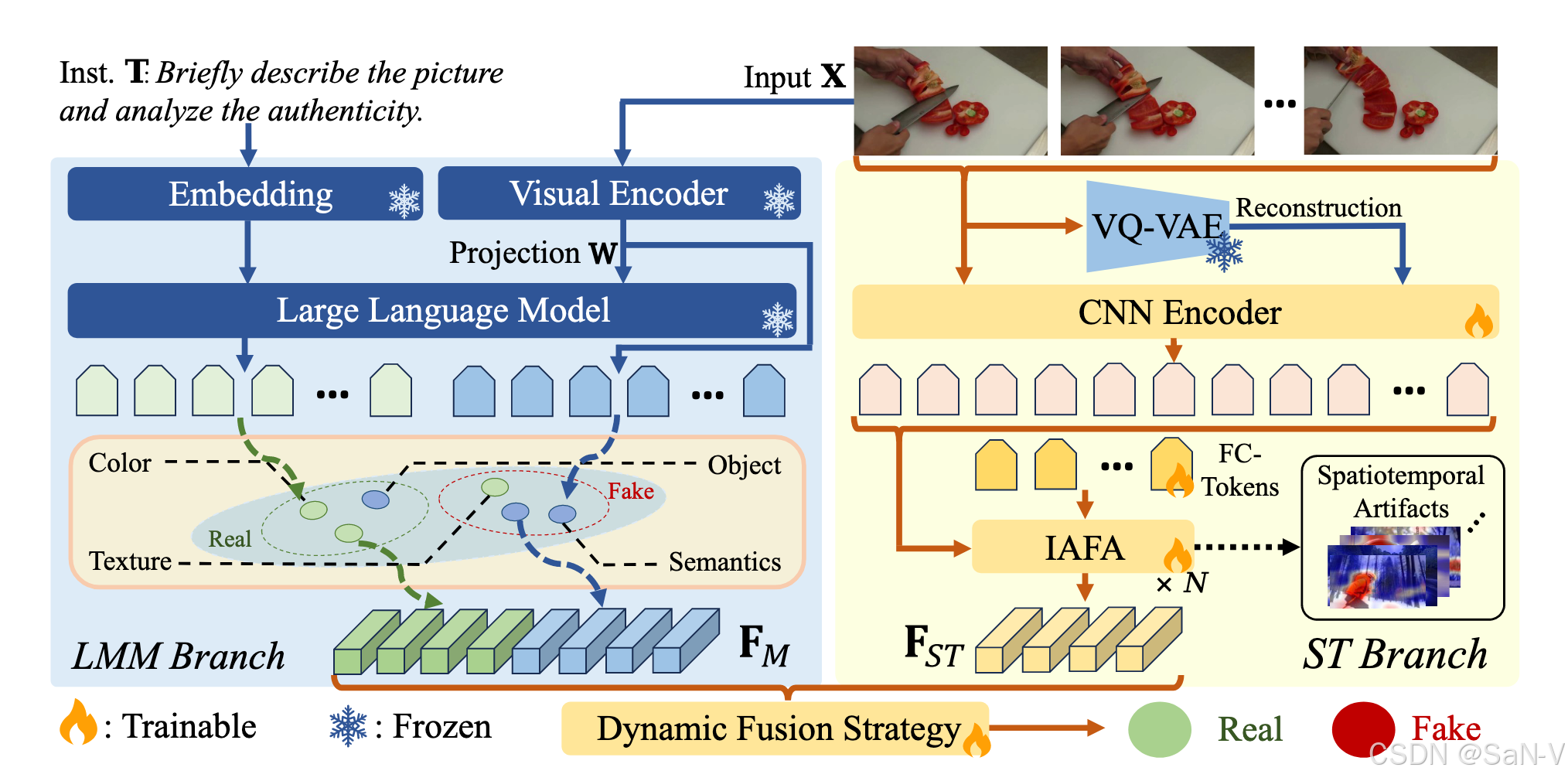
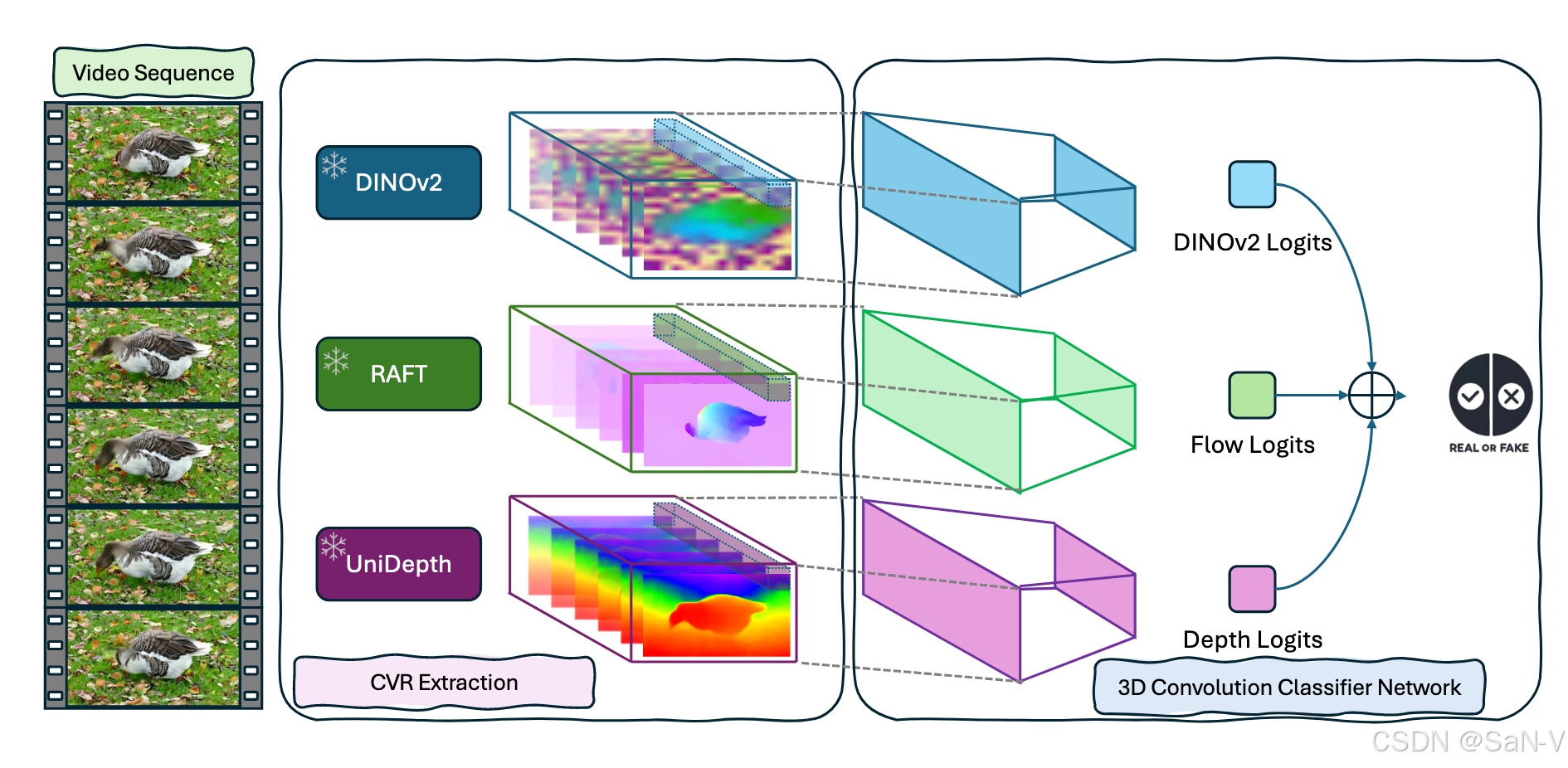
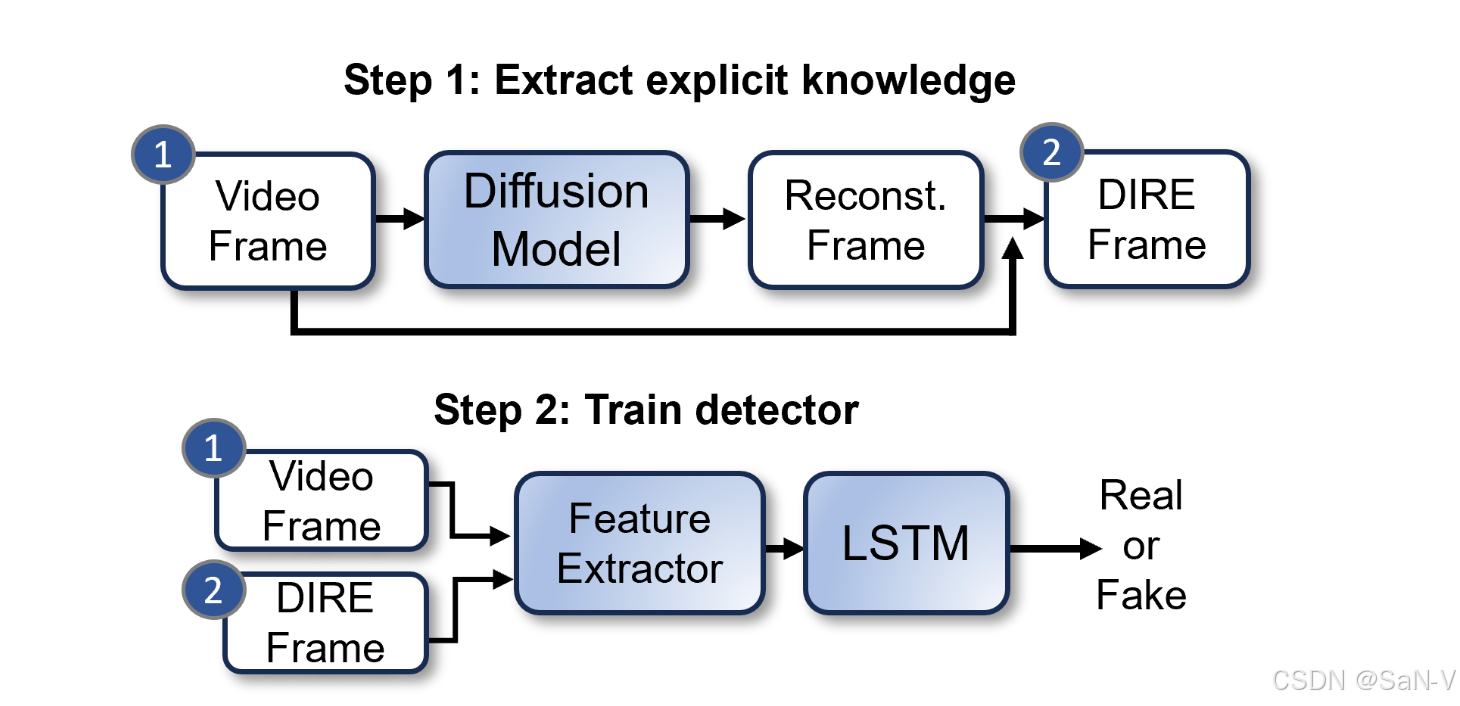

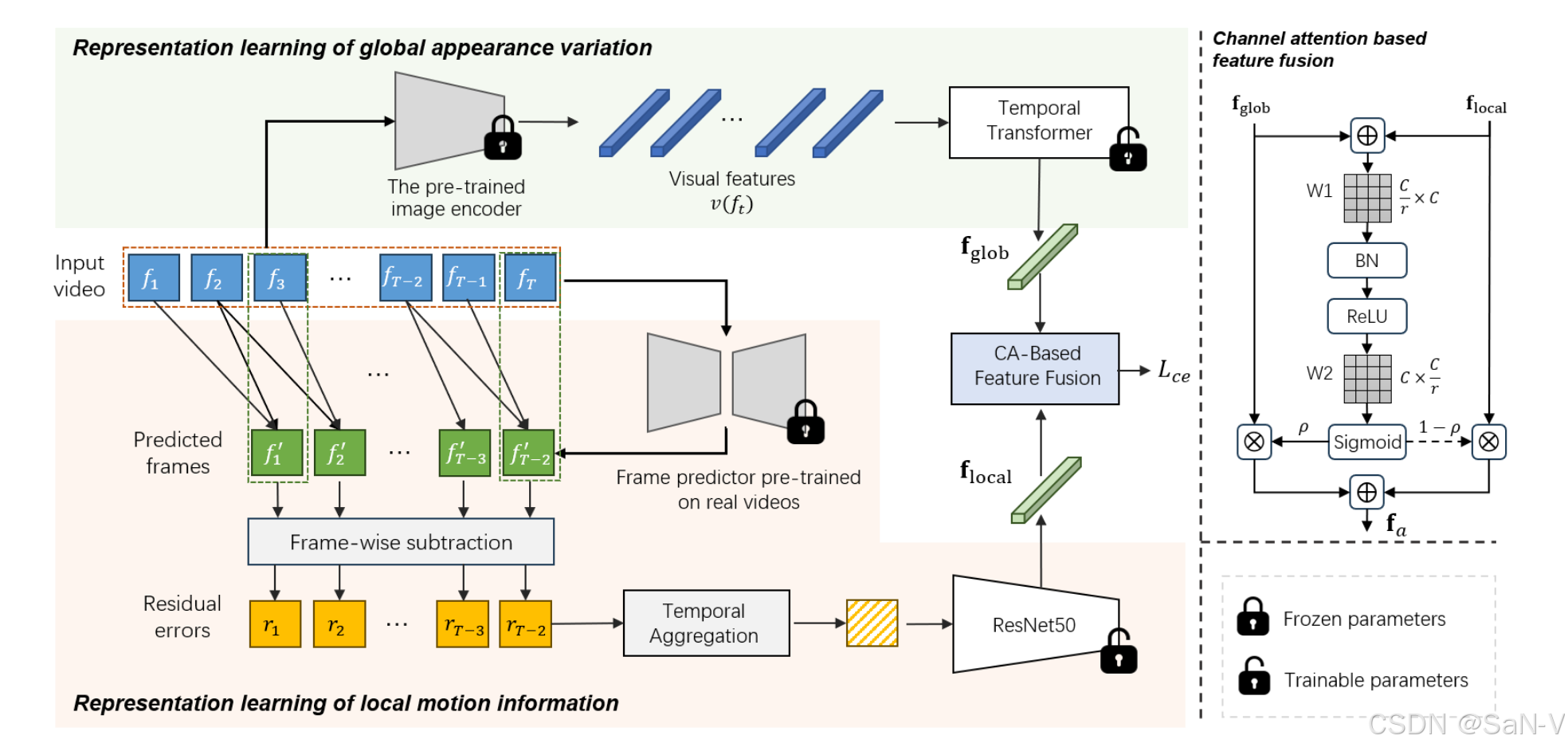

everything-claude-code:Agent Harness 性能优化系




 关注微信
关注微信