时间:2026-03-13 14:09
人气:
作者:admin
3D 语义占用预测是自动驾驶感知的核心任务,它能为车辆提供周围环境的精细几何表征和语义信息,是后续导航、运动规划、碰撞避障的核心基础。但现有纯视觉方案普遍面临两大行业痛点:一是 2D-3D 视图变换中,因深度精度不足导致的几何特征错位,二是语义类别空间分布不均带来的长尾类别识别困难。
这篇论文《Dr.Occ: Depth- and Region-Guided 3D Occupancy from Surround-View Cameras for Autonomous Driving》,就针对这两个核心问题提出了一套端到端的统一解决方案。
它通过深度引导的双投影视图 Transformer(D2-VFormer) 从根源解决几何对齐难题,通过区域引导的递归专家 Transformer(R2-EFormer) 针对性缓解语义长尾失衡,最终在权威的 Occ3D-nuScenes 基准上,将强基线 BEVDet4D 的 mIoU 大幅提升 7.43%,IoU 提升 3.09%,同时具备极强的模块泛化性和工程落地价值。
论文:Dr.Occ: Depth- and Region-Guided 3D Occupancy from Surround-View Cameras for Autonomous Driving

图1. Dr.Occ.的整体架构. T个连续的环视图像由MoGe-2处理生成估计深度图,这些深度图为D2-VFormer提供了几何线索,用于构建密集、低成本且几何精确的体素特征。随后,这些特征在R2-EFormer中通过递归语义解码进行细化。最后,经过细化的特征由OCC解码器解码,生成占用预测结果
Dr.Occ 的整体架构完全贴合主流 3D 占用预测的 pipeline,同时做了两个核心的、可即插即用的模块创新,整体流程如下:
图像编码:用 ResNet50 backbone 提取多帧环视图像的 2D 语义特征;
深度先验提取:用预训练 SOTA 模型 MoGe-2,同步生成像素级深度图和密集深度特征;
核心模块 1:D2-VFormer:深度引导的双投影视图变换,完成 2D 特征到 3D 体素空间的精准映射,输出几何对齐的体素特征;
核心模块 2:R2-EFormer:区域引导的递归专家变换,针对语义空间分布特性,自适应分配模型容量,完成语义特征精修;
3D 占用解码:将精修后的特征上采样,通过轻量 CNN 输出最终的体素级语义占用预测结果。
两个模块的协同逻辑非常清晰:深度引导模块是基础,解决 “位置对不对” 的问题;区域引导模块是上限,解决 “类别准不准” 的问题。没有精准的几何对齐,语义学习就是空中楼阁;没有自适应的语义建模,几何再准也突破不了精度瓶颈。
D2-VFormer 的全称是 Depth-guided Dual-Projection View Transformer,是论文解决几何错位问题的核心,它没有完全推翻传统的投影范式,而是把高精度通用深度先验,深度融合到了前向 + 后向的双投影流程中,既规避了通用深度的域差距问题,又解决了传统投影的几何错位缺陷。

图2:深度引导的双投影视图变换器
论文选用了预训练大模型 MoGe-2 提供深度先验 —— 该模型在开放域实现了像素级的高精度单目深度估计,自带公制尺度和精细的边缘细节,比传统任务内学习的深度精度高得多。
但论文做了消融实验验证:直接用 MoGe-2 的深度图做初始前向投影,性能反而会下降,核心原因有两个:
训练集不同:MoGe-2 是在开放域通用图像上预训练的,而自动驾驶任务聚焦城市场景、固定环视相机配置、0-50m 的近距离深度范围,直接用会出现尺度偏移、场景适配性差的问题;
特征空间不同:MoGe-2 的深度编码器和 Dr.Occ 的图像编码器(ResNet50)不是联合训练的,两者的特征空间不匹配,直接拼接或投影会导致特征错位,反而不如端到端联合优化的深度分布适配任务。
所以论文最终采用了 “各司其职、优势互补”的策略:
用 BEVStereo 的多帧前向投影做 “打底”:生成和任务适配、与图像特征对齐的初始稀疏体素特征,保证基础几何框架的稳定性;
用 MoGe-2 的高精度深度做 “精修”:通过几何掩码引导、深度特征融合,修正初始投影的几何错位,把精度拉到上限。
这是D2-VFormer 的设计灵魂,也是区别于传统双投影方法的核心:先用 MoGe-2 的深度图,提前锁定 3D 空间里 “有几何意义的非空体素”,让后续所有计算都聚焦在有效区域,既减少 90% 的无效计算,又避免空区域生成噪声特征。
掩码生成的完整流程,对应论文中的公式 (1)(2)(3):
公式 1:像素坐标 → 相机坐标系 3D 点
公式作用:把 2D 图像上的一个像素点,转换成相机镜头坐标系下的真实 3D 坐标,这是从 2D 到 3D 的第一步。
符号解读:
(u,v):2D 图像上的像素坐标;
d=Di(u,v):第 i 个相机的深度图中,该像素对应的公制深度值,来自 MoGe-2 的输出;
K:第 i 个相机内参矩阵的逆矩阵,作用是把像素齐次坐标,转换成相机坐标系下的归一化方向向量;
x:最终输出的、该像素在相机坐标系下的 3D 点坐标。
公式 2:相机坐标系 → 自车坐标系 3D 点
公式作用:把相机坐标系下的 3D 点,转换到统一的自车坐标系下,让不同相机的 3D 点能放到同一个空间里。
公式 3:3D 点集体素化,生成二值掩码
公式作用:把所有环视相机、所有像素反投影得到的 3D 点,转换成体素级的二值掩码,标记每个体素是不是 “非空的有效区域”。
符号解读:
v:3D 体素的中心坐标;
P:所有像素反投影得到的 3D 点集合;
r:预定义的体素分辨率(论文中固定为 0.4m);
Voxelize(⋅):体素化操作,把 3D 点分配到对应的体素格子里;
掩码含义:M(v)=1代表该体素是有几何意义的非空区域,M(v)=0代表该体素是空区域。
D2-VFormer 采用 “前向投影打底→后向投影补全→深度引导精修” 的三阶段递进式设计,每一步都有明确的目标和对应的操作:
Stage 1:前向投影与下采样
核心目标:完成 2D 特征到 3D 空间的初步映射,生成带几何基底的稀疏体素特征,同时通过下采样降低计算量、提升鲁棒性。
核心操作:参考 BEVStereo 的多帧前向投影范式,先通过自车位姿把过去帧的特征对齐到当前帧坐标系,再为每个 2D 特征点预测深度概率分布,沿相机视锥把 2D 特征 “提升” 到 3D 空间,最后聚合得到初始稀疏体素特征(初始占用率约 30%)。
关键操作:对初始体素特征Fdown和几何掩码M做 4 倍下采样,得到Fdown和Mdown。论文里明确了下采样的两个核心收益:① 大幅降低后续注意力模块的计算量;② 更粗的体素粒度,能容忍像素级深度估计的微小误差,避免精细粒度下深度误差被放大。
Stage 2:后向投影致密化
核心目标:弥补前向投影稀疏特征的几何残缺,通过后向投影的跨视图融合,补全体素特征的完整性。
核心变换公式:
设计考量:前向投影的特征是稀疏的,存在几何残缺,后向投影通过 3D 体素主动查询 2D 图像特征,能补全遗漏的区域;但无约束的后向投影会在无几何证据的空区域生成噪声特征,这也是必须要有 Stage3 深度引导精修的原因。
Stage 3:深度引导的非空体素两步精修
这是D2-VFormer 的核心创新环节,基于Mdown掩码,完全区分非空体素和空体素的处理逻辑:仅对非空体素做精细化的几何 + 语义双重优化,空体素直接跳过,既保证精度,又控制计算量。
整个阶段分为先后两步,先做几何精修,再做语义增强:
第一步:几何精修
核心目标:用 MoGe-2 的高精度深度特征,修正体素特征的几何一致性,解决投影带来的几何错位问题。
公式解读:
第二步:语义增强
核心目标:在几何精修的基础上,再次融合多视图图像的语义特征,优化非空体素的语义表达,为后续的语义分类提供更丰富的特征支撑。
公式解读:延续掩码约束的思路,仅对非空体素执行 DCA 注意力融合,以几何精修后的特征Fgeo为 query,以原始图像语义特征F(I)为 key/value,进一步补充体素的语义细节,最终输出整个D2-VFormer 模块的最终特征Fout。
在解决了几何对齐的基础问题后,论文针对语义长尾失衡的痛点,基于自动驾驶场景 “语义强空间各向异性” 的核心观察,设计了两款递进式的 Transformer 结构:固定分区的R-EFormer,和自适应递归的 R2-EFormer(论文最终推荐的最优版本)。

图3: (a–b) 空间语义分布揭示了沿高度和距离方向的强烈各向异性。 (c–d) R-EFormer 将三维空间划分为一个 3×3 的空 间网格,分别沿距离(近、中、远)和高度(低、中、高)维度进行划分,并为每个区域分配一位专门的专家。 (e) R2 EFormer 通过递归掩码自适应地细化各个区域
这是整个模块的设计根基,论文通过统计分析,发现了自动驾驶场景的核心规律:不同语义类别在 3D 空间里,有极强的位置偏好:
高度维度:可行驶路面、人行道集中在 - 1.0m~0.2m 的低高度区;车辆、行人、骑行者集中在 0.2m~2.2m 的中高度区;建筑、植被集中在 2.2m~5.4m 的高高度区。
距离维度:自车周边的路面、路沿集中在 0~10m 的近区;动态障碍物核心聚集在 10~30m 的中区;远距离静态背景集中在 30m 以上的远区。
这个规律带来了一个关键结论:把 3D 空间按语义分布分区后,每个区域内的语义类别集中度会大幅提升,稀有类别的相对占比显著提高,监督信号被有效放大。比如在 “中距离 + 中高度” 的区域,车辆、行人的占比远高于全空间,模型不用再被海量的路面、空体素特征干扰,能更聚焦于关键类别的学习。
R-EFormer 是基于混合专家(MoE)框架设计的,核心逻辑是 “手动空间分区 + 区域专属专家 + 路由自适应激活”,让每个专家只负责自己擅长的区域,降低学习难度。
完整流程分为 4 步,对应论文中的公式
步骤 1:固定空间分区
论文基于语义分布规律,把整个 3D 体素空间,沿距离和高度两个维度,划分为 3×3=9 个固定的空间区域,每个区域Rm(m=1~9)都预先生成对应的二进制空间掩码Mm。
步骤 2:路由打分与专家激活
为了兼顾效果和计算效率,R-EFormer 不会同时激活全部 9 个专家,而是通过路由网络自适应选择当前场景最重要的区域,仅激活对应的专家。
区域重要性打分
公式作用:给 9 个固定区域分别计算一个重要性得分,判断当前场景里哪些区域是需要重点关注的。
符号解读:
Top-K 专家激活
公式作用:只选取得分最高的 K 个区域,仅激活这些区域的专家,其余专家完全不参与计算,大幅降低计算开销。
步骤 3:区域专属专家建模
公式作用:对每个被激活的区域,用专属专家完成该区域内的语义特征精修。
解读:每个专家的核心还是带掩码约束的 DCA 模块,以全局体素特征为 query,以多视角图像特征为 key/value,但区域掩码Mm会严格限制 DCA 的计算范围 —— 仅对该区域内的体素执行注意力计算,区域外完全不参与。每个专家只需要学习对应区域的语义分布,学习难度大幅降低,对区域内的稀有类别捕捉能力显著增强。
步骤 4:多专家输出融合
公式作用:把所有被激活专家的输出,按路由得分做加权融合,得到最终的语义精修特征。
符号解读:wm是第 m 个区域的归一化权重,由路由得分sm做 softmax 归一化得到,重要性越高的区域,权重越大;未被激活的区域权重为 0,不参与融合。
R-EFormer 的优势是强先验适配、可解释性强,但也有局限性:手动分区存在超参敏感性,9 个独立专家带来了额外的参数量,固定分区无法适配同区域内的体素级难度差异。
为了解决 R-EFormer 的缺陷,论文基于混合递归(MoR)思想,设计了进阶版的R2-EFormer,改进是:摒弃手动固定分区,用单个共享专家做多轮递归迭代,渐进式聚焦高难度体素,实现自适应的语义精修。
论文中采用 3 轮递归迭代,设置了递减的体素覆盖比例:100%→75%→50%,实现从全局粗修到难例精修的递进,核心流程对应论文公式 (11)(12):
第一步:迭代式掩码生成
公式作用:每一轮迭代生成对应的掩码,决定本轮专家计算的聚焦范围,掩码随迭代逐步收缩,仅保留高重要性的体素。
符号与逻辑解读:
t:迭代轮次,论文中 t=1,2,3;
初始轮(t=1):掩码M(1)为全量体素空间Ω,覆盖 100% 体素,先对全局做基础的语义精修,保证整体语义的一致性;
R(t):本轮的轻量路由网络,输入是上一轮的输出特征F(t−1)和上一轮的掩码M(t−1),输出体素级的重要性权重图;
Kt是递减序列:论文中 3 轮迭代的覆盖比例为 100%→75%→50%,保证掩码逐步收缩,聚焦高难度体素;
核心约束:M(t)⊂M(t−1),本轮的掩码范围完全包含在上一轮的掩码内,确保迭代是渐进聚焦,不会跳脱之前的学习范围。
第二步:递归式特征精修
公式作用:用同一个共享的 DCA 专家模块,基于本轮的掩码,对聚焦区域的体素做语义精修,迭代优化特征表达。
符号与逻辑解读:
F(t−1):上一轮迭代输出的体素特征,作为本轮 DCA 的 query;
F(I):当前帧多视角图像特征,作为 key/value,持续补充细粒度语义线索;
M(t):本轮的聚焦掩码,严格限制 DCA 仅对掩码内的体素做注意力计算,掩码外的体素特征直接继承上一轮结果,不参与计算;
n:总迭代轮次,论文中固定为 3。
最终,最后一轮迭代输出的F(n),就是R2-EFormer 的最终输出,直接送入后续的 3D 占用解码器。
对比 R-EFormer,R2-EFormer 的优势非常明显:
参数量大幅降低:单个共享专家替代 9 个独立专家,无额外参数量开销;
无手动超参依赖:无需人工定义分区规则,模型自适应学习体素级的重要性,泛化性更强;
难例优化能力突出:渐进式收缩的掩码,让模型把计算资源集中在语义模糊、识别难度高的体素上(如遮挡的行人、小交通锥),对长尾稀有类别的优化效果更显著。
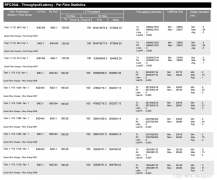
论文在权威的 Occ3D-nuScenes 基准上做了全面的实验验证,从定量 SOTA 对比、模块消融实验、定性可视化三个维度,充分证明了 Dr.Occ 的有效性。
数据集:Occ3D-nuScenes,包含 850 个带标注的自动驾驶城市场景,标注范围是自车周围 80m×80m×6.4m 的 3D 空间,体素分辨率 0.4m,共 18 个语义类别。
评价指标:
IoU:二值占用的交并比,衡量几何重建的精度;
mIoU:所有语义类别的平均交并比,是衡量语义理解能力的核心指标。
实现细节:图像编码器用 ResNet50,深度估计用 moge-2-vits-normal,模型训练 24 个 epoch,在 8 张 NVIDIA L20 GPU 上完成训练。
论文对比了三类主流的 3D 占用预测方法:前向投影方法(FlashOcc、BEVDet4D)、后向投影方法(BEVFormer、TPVFormer)、双投影方法(FB-Occ、COTR),核心结果如下:

| 方法 | 骨干网络 | 输入尺寸 | mIoU(%) | 核心提升 |
|---|---|---|---|---|
| BEVFormer | R101 | 1600×900 | 26.9 | - |
| TPVFormer | R101 | 1600×900 | 41.2 | - |
| FlashOcc | R50 | 704×256 | 37.8 | - |
| BEVDet4D(基线) | R50 | 704×256 | 36.0 | 基线 |
| BEVDet4D + Dr.Occ | R50 | 704×256 | 43.4 | 比基线 + 7.43% mIoU |
| COTR(SOTA 基线) | R50 | 704×256 | 43.1 | 同期 SOTA |
| COTR + Dr.Occ | R50 | 704×256 | 44.1 | 比 SOTA 再 + 1.0% mIoU |
| 几何模块(D2-VFormer) | 语义模块(R-EFormer) | 语义模块(R2-EFormer) | IoU(%) | mIoU(%) | 增益说明 |
|---|---|---|---|---|---|
| ❌ | ❌ | ❌ | 70.36 | 36.01 | 基线 |
| ✅ | ❌ | ❌ | 71.29 | 41.45 | 仅几何模块,mIoU+5.44%,IoU+0.93% |
| ✅ | ✅ | ❌ | 73.45 | 43.03 | 叠加 R-EFormer,mIoU 再 + 1.58% |
| ✅ | ❌ | ✅ | 72.87 | 43.43 | 替换为R2-EFormer,实现最高 mIoU,再 + 0.4% |

图4:深度引导的双投影的优势

图5:专家模型下的语义增强的优势
R2-EFormer 的核心设计是100%→75%→50% 的渐进式掩码收缩,每一轮迭代仅保留上一轮特征中重要性排名靠前的体素,后续轮次的掩码完全包含在上一轮的范围内。这种设计虽然实现了难例聚焦,但带来了两个固有问题:
初始轮特征对长尾小目标(如交通锥、远距离行人)的响应度低,会在第一轮的 Top-K 筛选中被直接过滤,后续轮次完全失去优化机会,反而加剧了小目标的漏检风险;
若初始轮对物体的语义边界预测错误,后续轮次只会在错误的边界内精修,无法修正边界范围,导致错误被固化,影响目标轮廓的预测精度。
改进方向:打破掩码的严格收缩约束,设计 “全局 - 局部” 双分支递归结构,全局分支保留全量语义上下文,局部分支聚焦高重要性体素精修;同时引入类别感知的路由机制,对长尾稀有类别设置专属的重要性权重,避免小目标在迭代中被过滤。
Dr.Occ 仅在初始前向投影阶段,用多帧时序信息做立体匹配增强深度估计,在后续的核心几何精修、语义精修模块中,完全没有利用时序上下文信息。而自动驾驶场景中,连续帧的时序信息,是解决当前帧遮挡、运动模糊、动态物体预测的关键线索。对于被短暂遮挡的动态物体,仅靠当前帧的视觉信息无法完成准确的占用预测,而 Dr.Occ 完全没有利用时序的运动先验与历史特征,导致动态遮挡场景下的性能存在明显短板。
改进方向:在D2-VFormer 和R2-EFormer 中引入时序时空注意力模块,融合历史帧的体素特征与运动信息,用时序上下文补充当前帧的视觉信息缺失,提升动态遮挡场景的预测鲁棒性。
D2-VFormer 对掩码标记的空体素,直接采用全局共享的可学习空嵌入eempty,不参与注意力计算,虽然节省了计算量,但带来了两个问题:
一是深度掩码漏检的障碍物,会被直接赋值空嵌入,完全失去修正机会,导致漏检;
二是不同空间区域的空体素的语义上下文差异极大,全局共享的单一嵌入无法表征这种差异,容易引发边界处的误检与漏检。
改进方向:设计分层的空体素建模机制,对空体素按空间区域、语义上下文做分类建模,保留低置信度空体素的优化空间;同时引入空 - 非空的边界感知损失,强化对占用边界的建模,减少边界处的预测错误。


 关注微信
关注微信