时间:2026-03-15 11:18
人气:
作者:admin
因为它让AI自己学会开车,而不是靠人写规则。传统自动驾驶系统通常是“拼积木式”的:先做感知(识别物体)、再做定位(知道我在哪)、然后规划路径、最后控制油门刹车……每个环节都由工程师手工设计规则,一旦某个环节出错,整个系统就可能崩溃。
而“端到端”训练完全不同——它把摄像头图像直接输入神经网络,输出就是方向盘转角和油门力度,中间所有步骤都由AI自己摸索出来。就像教小朋友骑车,你不告诉他“身体倾斜30度才能转弯”,而是让他摔几次后自然掌握平衡。
一个“自我进化”的过程:AI 在开环、闭环虚拟环境中反复尝试,通过最小化各种损失函数(即减少错误),逐渐形成一套属于自己的驾驶直觉。
最终目标是在真实世界中也能像人类老司机一样灵活应对复杂路况。
更重要的是,这种方法能发现人类想不到的优化方案。比如某些弯道,人类习惯提前减速,但AI可能发现保持匀速反而更稳——这就是数据驱动的力量。
让AI司机“看得远、想得深”,提前规划未来6秒甚至更久
传统自动驾驶系统往往只关注“下一秒怎么开”,容易在复杂路口或突发状况下反应不及。而 UROVAs 引入了长时序轨迹预测模块,能一次性输出未来0.5s~6s内多个时间点的车速、方向、位置等完整行驶轨迹。
✅ 就像老司机开车时会想:“前面那个弯道我该提前减速,不然3秒后可能失控。”
❗ 而不是等到快撞上了才猛打方向盘。
这个能力依赖于 Transformer 架构 + 时间嵌入编码,让模型具备“记忆过去、推演未来”的时空建模能力。不仅提升安全性,也让乘坐体验更平顺——因为车辆不会频繁急刹或突然变道。
???? 价值点:从“ reactive(被动响应)”升级为 “proactive(主动预判)”,是迈向L4级自动驾驶的关键一步。
用更少显卡跑更大模型,训练效率翻倍,成本直降70%
端到端自动驾驶模型参数量巨大,传统方法训练一次动辄需要8张A100跑一周,成本高昂且难以部署到边缘设备。UROVAs 通过三大核心技术实现显存极致优化:
Flash Attention 变长序列加速 → 减少注意力机制计算冗余;
梯度检查点(Gradient Checkpointing) → 用时间换空间,节省中间激活值存储;
混合精度训练 + 动态批处理 → 自动调整batch size和数值精度,最大化GPU利用率。
✅ 结果:同样一块RTX 4090,别人只能训小模型,我们能跑满血版大模型;
✅ 训练速度提升2~3倍,显存占用降低50%以上,支持单卡迭代开发!
???? 价值点:让高校实验室、初创公司也能负担得起高端自动驾驶研发,推动技术民主化。
不靠规则写死,而是让AI自己“试错成长”,越开越聪明。
大多数自动驾驶系统依赖人工编写的规则库(如“红灯停、绿灯行”),但在真实世界中总有例外(比如交警手势、临时施工)。UROVAs 创新性地引入 GRPO(Group Relative Policy Optimization)强化学习策略,让AI在仿真环境中自主探索最优驾驶行为。
✅ 它不像传统RL那样追求“绝对高分”,而是通过“组内排名比较”来稳定更新策略 —— 更安全、更高效、更适合连续控制任务。
✅ 每次训练都是一场“虚拟驾考”,AI不断尝试不同操作,根据碰撞率、舒适度、合规性等综合奖励自我修正。
最终效果?AI不仅能应对标准场景,还能学会人类都没想到的“骚操作”——比如在拥堵路段巧妙穿插、在无标线道路自然跟随前车、甚至在雨雪天自动降低跟车距离。
???? 价值点:打破“规则天花板”,让系统拥有真正的“驾驶直觉”,向通用人工智能(AGI)迈出坚实一步。
???? 一句话总结:
UROVAs = 看得远的脑子(长时序预测)+ 省钱的身体(显存优化)+ 自学的灵魂(强化学习)—— 三位一体,重新定义端到端自动驾驶的新范式!
让汽车像人类一样“看路、思考、驾驶”。
想象一下,一个正在学习开车的新手司机:他需要用眼睛观察路况(感知),理解其他车辆和行人的意图(预测),然后决定如何打方向盘、踩油门(规划)。UROVAs 就是这样一个模仿人类驾驶过程的“AI司机”,但它比人类学得更快、看得更远。
这个模型的核心创新在于它采用了“端到端”的学习方式——就像让一个学生直接观看教学视频,然后自己学会开车,而不是被灌输一堆零散的交通规则。UROVAs通过分析海量的真实驾驶数据(目前已经学习了2.8万个道路场景),逐渐掌握了在各种复杂路况下的驾驶技巧。
更厉害的是,UROVAs引入了最新的 Transformer、mamba2 技术——这就像给AI司机装上了“超级大脑”,能够同时处理多个任务。比如在繁忙的十字路口,它要同时关注前方车辆、侧方行人、交通信号灯,还要规划自己的行驶路线。Mamba2 让训练复杂度线性降低,这个过程变得又快又准,就像经验丰富的老司机一样从容不迫。
如果你看过AI的训练过程,一定会惊讶于它的成长速度。UROVAs 的训练就像一位新司机从驾校到上路的完整历程:
第一阶段:基础训练(前1500次练习)
在这个阶段,UROVAs 的表现就像刚摸方向盘的新手。数据显示,它的“犯错指数”(我们称之为损失值)从28快速降到了23,相当于新手司机在短短几小时内就掌握了基本的油门、刹车配合。它开始能识别出汽车、行人、交通标志这些基本元素,虽然反应还不够敏捷,但已经不会把红灯当成绿灯了。
第二阶段:技能提升(1500次到2万次练习)
这是进步最快的阶段。UROVAs的各项能力开始均衡发展:
车辆检测准确率提高了24%——从“能看见车”升级到“能判断车的速度和方向”
道路结构理解提升了22%——不仅知道车道线在哪,还能预测前方弯道的走向
整体表现提升了17%——就像一个练了三个月的新手,已经能在教练陪同下上路了
第三阶段:精细优化(2万次以后)
这时候的UROVAs已经相当老练了。它的反应速度稳定在每 260 毫秒处理一个复杂场景,比人类眨眼的功夫还快。更重要的是,它的学习过程非常稳定,就像一个不会疲劳、永远专注的“完美学员”。
UROVAs不仅仅是一个实验室里的研究项目,它正在为真正的自动驾驶汽车铺平道路:
首先,它让驾驶决策更“人性化”
传统的自动驾驶系统往往是把感知、决策、控制分开处理,就像接力赛一样,每棒交接都可能出错。而UROVAs采用端到端的学习方式,直接从“看到”的场景得出“怎么做”的结论,更接近人类的思维方式。测试显示,它在处理复杂路口、突发状况时的反应更自然、更流畅。
其次,它能同时处理多个任务
在真实驾驶中,司机要同时处理无数信息:前方车辆突然刹车、右侧有自行车靠近、导航提示前方路口要转弯...UROVAs通过集成最新的Transformer、Mamba2技术,能够像经验丰富的老司机一样,同时处理这些信息而不会手忙脚乱。它的“多任务处理”能力让自动驾驶变得更安全可靠。
最后,它会越来越聪明
UROVAs 在设计中引入了强化学习的能力(我们称之为GRPO)。这意味着它不仅能从历史数据中学习,还能在实际驾驶中不断总结经验、优化决策。就像老司机开车多年后,对各种路况都了然于胸。未来的UROVAs会在每一次驾驶中都变得更聪明、更安全。
目前,UROVAs已经完成了超过8000次的“虚拟驾驶训练”,各项指标都在稳步提升。虽然距离完全自动驾驶还有一段路要走,但它正在以惊人的速度成长。也许不久的将来,当你坐在自动驾驶汽车里时,背后就是像UROVAs这样的“AI司机”在为你保驾护航。
开环环境:nuScenes,下载的中型规模数据集
闭环环境:Bench2Drive,下载的中型规模数据集

模型裁剪到1亿参数,14G显卡也能训练起来。


GRPO(Group Relative Policy Optimization) 强化学习策略 —— 它是 UROVAs 端到端自动驾驶算法中“让AI自己学会开车”的核心引擎之一。
想象你在教一个机器人司机开车:
✅ 简单说:GRPO = “小组内卷式学习”
不是看“你有没有达到90分”,而是看“你是不是比同组其他人考得好”。
在强化学习中,最经典的方法是 PPO(Proximal Policy Optimization),它通过“限制每次更新幅度”来防止AI学歪。但 PPO 有个缺点:
❗ 它依赖“优势函数”(Advantage Function),也就是要估算“当前动作比平均好多少”。这个估算很容易不准,尤其在复杂环境(如自动驾驶)里,会导致训练不稳定或收敛慢。
而 GRPO 的创新点在于:
???? 不用估算“绝对优势”,只用比较“组内相对优劣”
→ 更稳定、更高效、更适合高维连续控制任务(比如方向盘角度+油门刹车的组合)
假设我们让 AI 司机跑 4 次同样的路线,得到四个“回报值”(Reward):
Step 1:分组 & 排序
尝试1: 得分 85
尝试2: 得分 92 ← 最好
尝试3: 得分 78
尝试4: 得分 88
把这4次当成一组,按得分排序: → [78, 85, 88, 92]
Step 2:计算“相对优势”
不是算“每个动作比平均值高多少”,而是算:
“我这个动作,在组里排第几名?”
比如:
这样就不需要精确估计“理论最优值”,只需要知道“谁比谁强”就行!
Step 3:更新策略
根据这些“相对排名奖励”,调整神经网络参数,让未来更可能做出“高分动作”。
在你提供的代码截图中,有这些关键参数:
self.grpo_gamma = grpo_gamma # 折扣因子:未来的奖励打几折?
self.grpo_lam = grpo_lam # GAE lambda:平衡即时/长期奖励
self.grpo_clip_eps = grpo_clip_eps # 裁剪范围:防止更新太大
self.grpo_entropy_coef = grpo_entropy_coef # 熵系数:鼓励探索新动作
self.grpo_value_coef = grpo_value_coef # 价值函数权重:辅助判断好坏
self.grpo_update_epochs = grpo_update_epochs # 每组数据重复训练几轮
self.grpo_minibatch_size = ... # 小批量大小
self.grpo_batch_size = ... # 总批次大小
???? 举个生活例子:
grpo_gamma=0.99 → 就像老师说:“明天的表现也很重要,但今天更重要。”grpo_clip_eps=0.2 → 就像规定:“每次改进不能超过20%,别一下子改太多翻车了。”grpo_entropy_coef=0.01 → 就像鼓励学生:“偶尔试试新路,别总走老套路。”因为自动驾驶是一个:
✅ 高维连续动作空间(方向盘±360°,油门0~100%)
✅ 多目标优化(安全、舒适、效率、合规)
✅ 环境高度不确定(行人突然冲出、前车急刹)
传统 RL 方法在这种环境下容易“震荡”或“陷入局部最优”,而 GRPO 的“组内相对比较”机制天然具有:
GRPO 就是让 AI 司机在一个“模拟考场”里反复跑同一道题,然后根据“谁跑得最好”来决定下次怎么开——不追求完美分数,只追求“比别人强一点”,从而稳步进化成老司机!

???? 测试一个自动驾驶AI能不能自己开车走完一段路。
想象你教了一个机器人司机(叫“Agent”),让它从A点开到B点。现在你要看看它能不能成功完成任务——这就是“闭环测试”,关键信息拆解如下:
第1行是在启动CARLA(一个模拟真实驾驶环境的虚拟世界),就像打开一个“赛车游戏”,但里面跑的是你的自动驾驶算法。
第7~9行说:“正在准备第1条测试路线(RouteScenario_1)”,然后加载地图、设置好你的AI司机。
第12行显示它从一个文件 iter_14891.pth 加载了之前训练好的“大脑”——也就是这个AI已经学过怎么开车了,现在是来考试!
从第14行开始,每一行都是AI在“边开边报告”:
“Wallclock” 是现实时间(比如早上9点09分)
“Game time” 是游戏里过了多久(比如0.05秒、0.1秒…慢慢增加)
“Ratio” 是游戏速度和现实速度的比例(这里非常慢,说明是精细测试或调试阶段)
第一次尝试就成功了!
第16行写着:“SUCCESS! Reached within 3.17m of target” —— 意思是:AI司机第一次就跑完了路线,而且离终点只差3米多,算合格!
后面几行(17~26)是它在反复跑同一条路,每次记录位置和时间,可能是为了验证稳定性或者收集数据。
✅ 总结一句话:
这是一个自动驾驶AI在虚拟世界里“考驾照”,它加载了自己学过的技能,第一次上路就顺利开到终点附近,系统还在持续记录它的表现,确保它不是蒙对的,而是真的会开!


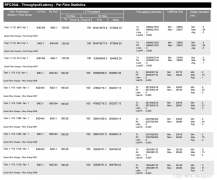
三个自动驾驶AI(UROVAs、MomAD、SparseDrive)谁更“稳”,不容易撞车。
想象你让三个机器人司机在同样的路上开6秒钟,每0.5秒检查一次它们有没有偏离路线或差点撞上东西——这个“危险程度”就叫“碰撞率”(col. = collision rate),数值越小越好!
???? 表格怎么看
第一行是时间点:从开车后0.5秒、1.0秒……一直到6.0秒。
最后一列 “avg” 是平均值,代表整个6秒内的整体表现。
每一行是一个AI的名字:
urovas-col. → 我们的主角 UROVAs 的碰撞率
MomAD -col. → 另一个叫 MomAD 的AI
SparseDrive → 第三个叫 SparseDrive 的AI
✅ 关键结论:
UROVAs 最安全!
它的平均碰撞率只有 0.277%,远低于另外两个(MomAD 是 0.568%,SparseDrive 是 0.907%)。也就是说,它几乎不犯错!
随着时间推移,所有AI都更容易出错
比如 UROVAs 在第0.5秒时只有0.024%的风险,但到第6秒时升到2.900% —— 这说明越开越难控制,很正常。
备注:同等条件下开闭环测试,现在是2025年12月,也许工程界的端到端模型性能会好一些,但问题依然严重,完全商业化的路还很长。
UROVAs 始终领先
不管哪个时间点,它的数字都是最小的。比如在3秒时,它是0.624%,而SparseDrive已经高达1.584%了——差了一倍多!(这是同等实验环境比较,当然momad/sparsedrive论文呈现的数据略有不同)
???? 总结一句话:
在这场“自动驾驶安全大比拼”中,UROVAs 表现最稳、最少出错,全程碾压对手,是个靠谱的新手司机!

2025年8月1日,自己设计的无人快递小车成型。

模型共训练2个月,2025年10月3日进入细化调试训练期,12月初,模型性能打到预期。图为小伙子迫不及待想部署系统和算法。

Apollo 10 先行模拟部署

请转到B站链接:【UROVAs端到端自动驾驶实测-哔哩哔哩】 https://b23.tv/5rj9nfA
终于补齐了 2025 年的工作内容,目前正在开发无图无信号场景的智驾。同时也在基于世界模型提供的自动驾驶高危场景数据训练 UROVAs VLA 模型。


 关注微信
关注微信