时间:2026-03-23 00:15
人气:
作者:admin
26年2月来自北京交大和小米EV的论文“DriveWorld-VLA: Unified Latent-Space World Modeling with Vision–Language–Action for Autonomous Driving”。
端到端(E2E)自动驾驶近年来日益受到关注,人们致力于将视觉-语言-动作(VLA)与世界模型相结合,以增强决策能力和前瞻性想象。然而,由于潜状态共享不足,现有方法无法有效地将未来场景演化和动作规划整合到单一架构中,从而限制了视觉想象对动作决策的影响。为了解决这一局限性,提出DriveWorld-VLA框架。该框架通过在表征层面紧密集成VLA和世界模型,将世界建模和规划统一在一个潜空间中,使VLA规划器能够直接受益于整体场景演化建模,并减少对密集标注监督的依赖。此外,DriveWorld-VLA将世界模型的潜状态作为VLA规划器的核心决策状态,帮助规划器评估候选动作如何影响未来场景演化。 DriveWorld-VLA 通过在潜空间中进行完全的世界建模,支持特征级别的可控、动作条件想象,避免昂贵的像素级展开。

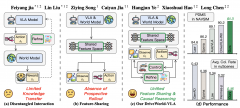
DriveWorld-VLA旨在将VLA模型与世界模型紧密集成到一个统一的架构中,该架构支持多模态推理和前瞻性想象。为了逐步协调表征学习、动作可控性和后果-觉察决策,采用一种三阶段训练范式。每个阶段逐步解锁世界模型的一项关键能力,同时确保与VLA的稳定联合优化。具体而言,训练过程分为三个顺序阶段:VLA与世界模型联合训练、动作可控性微调以及引导式评估与改进。如图展示DriveWorld-VLA的流程:
DriveWorld-VLA 支持多模态输入,包括多视角图像 I_t、文本提示 T_t、历史动作 A_t−1 和 BEV 表示 B_t。所有模态在输入视觉-语言模型 (VLM) 之前均独立进行token化。图像和文本token化遵循 InternVL (Zhu et al., 2025) 的方法,而 BEV 特征和历史动作则使用专用的token化器。BEV 特征 B_t 由 BEVFormer (Li et al., 2024c) 提取,进行空间展平,并投影到 VLM 嵌入空间作为 BEV token。历史自我动作被序列化为自然语言提示,并与文本指令连接,然后使用与 InternVL 相同的文本token化器进行编码。
Token化后,I_t、T_t、A_t−1 和 B_t 被联合输入到 VLM 中。 VLM 聚合所有模态的信息并生成一系列隐状态。从最终的 VLM 层提取隐藏状态作为共享的潜表示,记为 H_t,它作为未来想象和未来动作预测的公共特征空间。在此阶段,DriveWorld-VLA 经过训练,能够基于共享的潜表示联合执行未来想象和动作预测,从而促进世界模型知识向 VLA 的迁移。
未来想象在 BEV 空间中建模。去噪器以 H_t 和 B_t 作为输入,预测未来的 BEV 状态 B_t+∆t,然后由轻量级分割头 SEG 进行解码,
S_t+∆t = SEG_θ(B_t+∆t), S_t = SEG_θ(B_t′)。
去噪器包含一个历史条件分支和一个未来动作条件分支。在此阶段,仅激活历史条件分支,并强制执行基于历史观测的推理。这个轻量级分支提供密集的未来监督,从而实现预测性表征学习,并能有效地训练图像以适应 BEV token化器。未来动作条件分支遵循生成式范式,用于建模不同动作序列下可控的未来演化。
动作预测被建模为轨迹预测。一个轻量级动作解码器以 H_t、B_t 和 A_t−1 作为输入,输出预测的未来动作 A′_t+∆t:
A′_t+∆t = ACT_θ(H_t, B_t, A_t−1),
其中 ACT 表示动作解码器。
监督学习。未来的 BEV 状态通过解码语义 BEV 地图进行监督,而动作解码器则通过模仿专家动作进行监督。此阶段的总体损失定义为:
L_s_1 = L_seg + L_act,
其中 L_seg 监督语义 BEV 地图的解码,L_act 监督预测的动作。
在协同训练过程中,DriveWorld-VLA 并未对未来动作进行条件化,这使其无法基于预期动作来预测结果。因此,DriveWorld-VLA 无法在动作和未来场景生成之间形成闭环推理。理想情况下,DriveWorld-VLA 应该能够感知其动作如何影响环境的未来演化,从而评估动作质量,而不是仅仅依赖历史观测进行推断。
鉴于此局限性,本阶段致力于赋予 DriveWorld-VLA 基于动作进行未来预测的能力。由于 BEV 空间缺乏传感器观测数据,采用一种显式的特征级监督策略来进行 BEV 预测,这与 WoTE (Li et al., 2025c) 和 LAW (Li et al., 2024a) 等先前工作中使用的下游任务监督策略有着本质区别。经过协同训练后,由 BEV token生成器和 VLM 生成的 B_t′ 可以可靠地解码为语义 BEV 图。因此,将此 BEV 潜空间视为预训练的变分表示。给定未来的多视角图像 I_t+δt,重用第一阶段的编码流程来获得相应的真实 (GT) BEV 潜表示 B′_t+∆t。
随后,去噪器的第二分支采用基于 DiT 的架构来学习动作条件流匹配去噪过程,以 BEV 状态 B_t′ 和 GT 未来动作 A_t+∆t 作为条件,如图所示。监督损失记为 L_FM。
监督。在动作可控性微调阶段,总损失 L_s_2 仅由前面的损失 L_FM 构成。
本阶段旨在基于VLA与世界模型之间高度共享的表征H_t,建立动作预测与未来想象之间的闭环交互。DriveWorld-VLA不仅需要预测动作,还需要有效地想象这些动作所对应的未来结果,并根据想象的未来状态来评估和优化动作。给定B_t、H_t和A_t−1,DriveWorld-VLA首先预测未来动作A′_t+∆t,并通过第一个去噪分支生成未来想象B_t+∆t。随后,预测的动作被用于对第二个去噪分支进行条件化,该分支采用基于欧拉的采样方法生成动作条件化的未来想象B′_t+∆t。
为了评估预测动作的质量,综合考虑动作条件化的未来想象B′_t+∆t与对应的未来BEV表征B_t+∆t之间的一致性。学习的奖励函数 R 为每个预测轨迹分配一个标量分数 rˆ_t+∆t,真实奖励通过在模拟器中执行预测轨迹并进行在线评估获得。
除了轨迹质量评估之外,这种奖励驱动的设计还促进未来想象和动作生成之间的闭环。训练并非对所有多模态预测进行统一监督,而是优先考虑预测奖励更高的轨迹,强化那些能够带来更理想想象结果的轨迹,并实现后果-觉察的动作优化 L’_act。
监督阶段。在此阶段,去噪器和 VLM 被冻结。训练的重点是优化奖励函数和动作头。两个去噪分支生成的未来BEV潜变量被融合,并输入到分割解码器中进行监督式BEV解码,从而得到三个互补的监督信号:
L_s_3 = L′_act + L_seg + L_rew,
其中,L_seg 监督语义BEV图的解码,L′_act 监督由奖励加权的预测动作,L_rew 监督奖励函数 R。
实验中,对于NAVSIM,按顺序拼接左前视图、前视图和右前视图,形成一个256×1024的合成图像作为模型输入。用ResNet-34(He,2016)作为BEV编码器。训练采用 AdamW 优化器,初始学习率为 1e-4,批大小为 16。每个阶段在 8 个 NVIDIA H2O GPU 上训练 20 个 epoch,总训练时间约为 120 小时。对于 nuScenes 的开环评估,6 视图输入图像被调整为 640×384 像素。
采用 Swin-T(Liu,2021)骨干网络,并使用预训练权重进行初始化,然后使用 BEV-Planner(Li,2024d)对 BEV 特征图进行编码。训练采用 AdamW 优化器,初始学习率为 7e-5,批大小为 1。每个阶段在 8 个 NVIDIA H2O GPU 上训练 24 个 epoch,总训练时间约为 93 小时。需要注意的是,为了公平比较,所有基于 nuScenes 的实验均未使用自我状态信息。



 关注微信
关注微信