时间:2025-08-26 23:24
人气:
作者:admin
(1) 发表:BuildingTrust'25
(2) 背景
尽管对多智能体 LLM 系统(MAS)的热情越来越多,但与单机准则框架相比,它们在流行的基准测试中的性能往往仍然很少。这一差距强调了系统地分析阻碍 MAS 有效性的挑战的必要性
(3) 贡献
对 MAS 执行轨迹进行了首次系统评估,介绍了 MAS 的第一个结构性故障分类法(MAST),并结合 MAST 开发了一个 LLM-As-A-Judge 的评估框架来分析 MAS 的性能。开源了数据集和代码,包括 200 多个对话 Trace 以及详细的专家注释

提出失败模式的分类法是一个极具挑战性的任务,为了系统地发现没有偏见的失败模式,我们采用了基础理论(GT)方法。总体而言,GT 分析累积了150多个痕迹,需要每个具有代理系统经验的注释者超过 20 个小时的纯注释。为了完善分类法,我们进行了通知协议研究(IAA),8 名具有经验的专家通过添加、删除、合并、分裂或修改定义直到达成共识,从而迭代地调整故障模式和失败类别,为此一共进行了三轮 IAA 来解决注释之间的分歧
基础理论(GT)方法(Glaser&Strauss,1967):这是一种定性研究方法,该方法直接从经验数据中构建理论,而不是测试预定义的假设
(1) 数据收集
采用理论抽样来确保收集数据的一些列任务和质量的多样性,注释者们标注了 5 个 MAS 中的 150+ Traces。具体使用 open coding 来分析每个 Trace,将定性数据分解为标记的段,从而使注释者可以通过备忘录创建新的代码和文档观察结果,从而使注释者之间的迭代反射和协作
(2) IAA 研究
对于通道间协议(IAA)研究,我们就最初的分类学推导了三个主要的讨论。注释者致力于分类法以完善它,进行迭代改进,逐步改故障模式的定义,将它们分解为多个细粒度故障模式,将不同的故障模式合并到新的故障模式中,添加新的故障模式或根据需要删除分类学中的故障模式
这个过程可以比作一项学习研究,在学习研究中,不同的代理人(这次人类注释者)独立地从共同的状态空间收集观察结果,并彼此分享他们的发现以达成共识
(3) LLM 标注
目标是提出一种自动化的方法,以使用我们的分类法发现和诊断 MAS Traces 中的故障模式。为此,我们开发了一条 LLM-As-A-Judge 管道。在此策略中,本文提供了一个系统提示来让 LLM 给出包含我们 MAST 中分类故障的详细解释
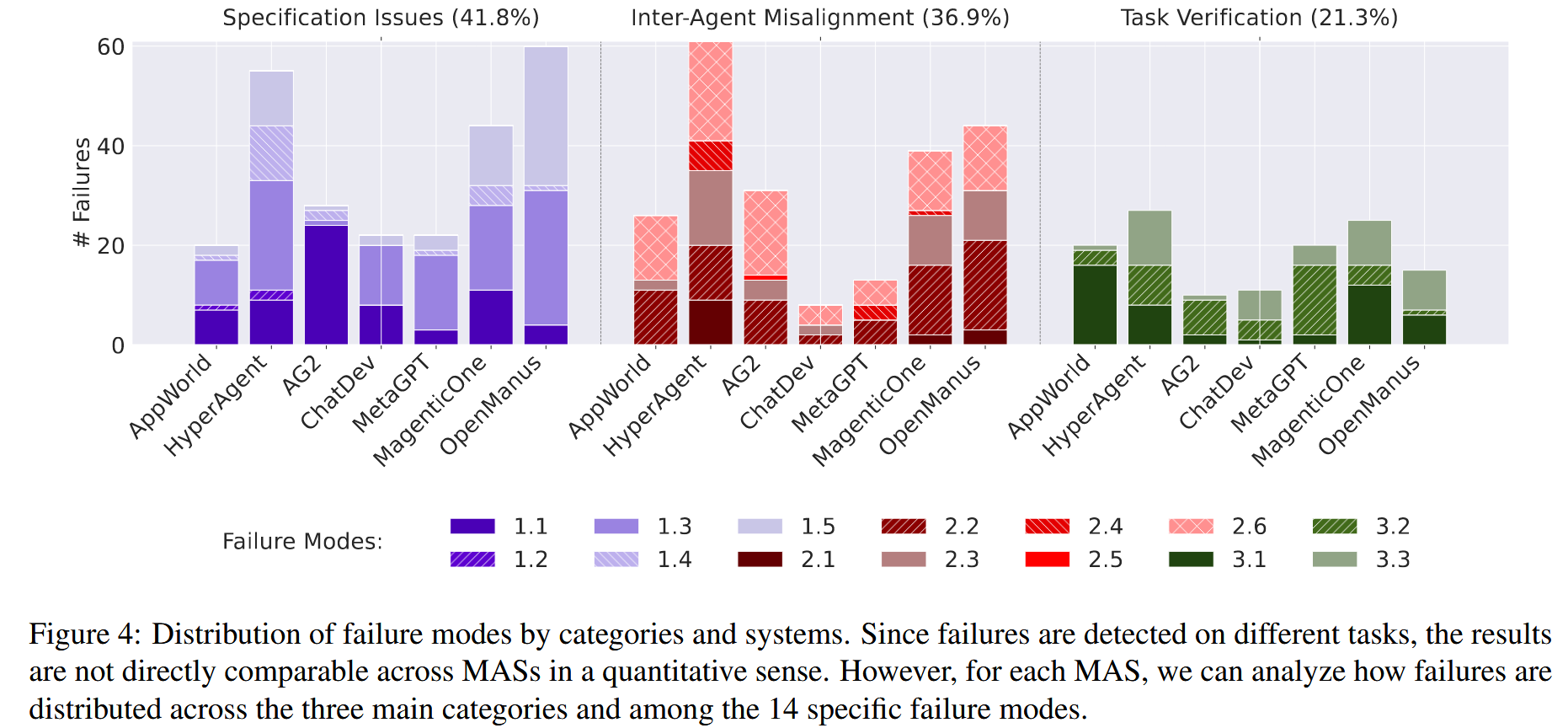
按照类别和系统的故障模式分布。由于在不同的任务上检测到故障,因此从定量意义上讲,结果在整个质量上都无法直接比较。但是,对于每个 MAS,可以分析如何在三个主要类别中以及14个特定故障模式中的故障分布
对基于 LLM 的多代理系统(MAS)的故障模式进行了首次系统研究。我们使用 GT 理论分析了 200 多个执行的 Traces,通过 IAA 研究进行了迭代改进和验证我们的分类学。最终确定了 14 种细粒失败模式,分为 3 个不同的类别,形成了多代理系统故障分类法 MAST
下一篇:读大语言模型08计算基础设施



 关注微信
关注微信