时间:2025-06-24 00:15
人气:
作者:admin
25年6月来自清华、上海姚期智研究院和北京中关村研究院的论文“What Can RL Bring to VLA Generalization? An Empirical Study”。
大型视觉-语言动作 (VLA) 模型已展现出具身人工智能 (embodied AI) 的巨大潜力。然而,它们主要通过监督微调 (SFT) 进行训练,由于在分布偏移下容易受到复合误差的影响,限制了其泛化能力。强化学习 (RL) 提供了一种克服这些限制的方法,它通过反复试验来优化任务目标,但对于 VLA 相较于 SFT 的具身泛化优势,缺乏系统的理解。为了解决这个问题,本研究引入一个用于评估 VLA 泛化的综合基准,并系统地研究 RL 微调在视觉、语义和执行等不同维度上的影响。大量的实验表明,RL 微调,尤其是使用 PPO 进行微调,在语义理解和执行鲁棒性方面显著增强 SFT 的泛化能力,同时保持相当的视觉鲁棒性。PPO 是一种比 DPO 和 GRPO 等 LLM 衍生方法更有效的 VLA 强化学习算法。本文还开发一种在 VLA 上进行高效 PPO 训练的简单方法,并证明了其对于提高 VLA 泛化能力的实用性。
视觉-语言-动作 (VLA) 模型代表一类新兴的基础模型 (Ma,2024;Firoozi,2023),它们统一了感知、语言理解和具身控制。通过利用在互联网规模数据上预训练的视觉-语言模型,并在大型异构机器人演示数据集上进一步训练 (Collaboration,2023;Khazatsky,2024),VLA 可以解读传感器观测数据和自然语言指令,并将其直接映射到机器人动作。该范式已在多种任务中展现出良好的泛化能力,包括单臂、双手和移动操作(Team,2024;Kim,2024;Liu,2024;Wen,2025)、导航(Shah,2022),甚至包括复杂的长时程活动,例如在未见过的场景中进行厨房或卧室清洁(Black,2024;Intelligence,2025)。
尽管前景光明,VLA 模型训练主要依赖于通过对演示标签进行行为克隆来进行监督微调 (SFT)(Kim,2025)。无论是在预训练还是小样本自适应中,这种方法在分布变化的情况下都本质上容易受到复合误差的影响:与专家轨迹的微小偏差可能会累积,导致策略进入不熟悉的状态,并损害稳健性能 (Ross & Bagnell, 2010; De Haan et al., 2019; Belkhale et al., 2023; Foster et al., 2024)。训练和测试分布之间的这种不匹配从根本上限制了稳健性,研究强调在这种情况下相对于任务范围的二次憾增长等问题 (Ross & Bagnell, 2010)。相比之下,强化学习 (RL) 提供了一种通过反复试验直接优化累积任务奖励的范式,使策略能够探索狭窄的专家数据之外的内容并学习纠正行为。至关重要的是,在更广泛的基础模型领域,尤其是在大语言模型 (LLM) 和视觉语言模型 (VLM) 方面,最近的研究强调强化学习在泛化方面的优势 (Ouyang et al., 2022; Zhai et al., 2024; Huang et al., 2025)。
有力的证据表明,虽然 SFT 倾向于记忆训练数据,但强化学习微调可以显著提高分布外性能,并释放更强大的推理能力 (Chu et al., 2025; Huang et al., 2025; Ma et al., 2025)。得益于强化学习在机器人技术领域的既定成功以及其他大模型所取得的令人鼓舞成果,强化学习微调正越来越多地应用于 VLAs (Collaboration,2023;Walke,2023;Khazatsky,2024),其方法多种多样,包括融入人类反馈 (Chen,2025) 到使用离线强化学习更新 (Zhang,2024b) 或 PPO 等算法 (Schulman,2017),有时还应用于具有模仿学习的多阶段过程 (Guo,2025b)。
然而,尽管做出了这些开创性的努力,对于强化学习微调赋予 VLA 的具身泛化优势(尤其是与 SFT 基线直接比较)以及它们各自优势差异的系统理解仍不够深入 (Hu et al., 2024; Mark et al., 2024)。例如,虽然近期的 FLaRe (Hu et al., 2024) 等研究证明 PPO 对 VLA 微调的实用性,但对所得模型泛化能力的全面分析并非其主要关注点。
研究重点放在具有代表性的拾取放置任务上。在这一任务中,首先评估主流的大规模强化学习 (RL) 算法(PPO (Schulman et al., 2017; Ouyang et al., 2022)、DPO (Rafailov et al., 2023; Zhang et al., 2024b)、GRPO (Shao et al., 2024; Guo et al., 2025a)),以确定有效的 VLA 微调策略。然后,进行广泛的比较评估,也涵盖拾取和放置 (pick-and-place) 任务,以找出强化学习微调优于 SFT 的领域。
如图所示,这项全面的评估从三个关键维度严格检验了泛化能力:1)视觉:挑战在新背景(未见过的桌子)以及在前景或整幅图像上叠加未见过纹理情况下的泛化能力。 2)语义:通过未见过的物体、新的容器和不同的指令措辞测试理解,以探究语言敏感性和物体识别。3)执行:通过改变机器人的初始状态、物体/容器的位置以及在情节中引入动态干扰(如随机物体重定位)来探测鲁棒性。

将每个语言调节的机器人任务 T 建模为部分可观察马尔可夫决策过程 (POMDP),定义为元组 M = (S, A, P, R, O, L, P (s_0), γ)。这里,状态空间 S 包括机器人和环境状态,A 是控制命令的动作空间,O 是传感器输出的观察空间。转换遵循 s_t+1 ∼P(· | s_t,a_t),γ 是折扣因子。每个任务 T 都有自然语言指令 L_T,当状态完成任务阶段或满足指令 l 时,会有奖励 R(s,l)。情节以指令 l ∼ L_T 和初始状态 s_0 ∼ P(s_0) 开始,这定义了机器人的初始姿势和环境。策略 π_θ 使用最近的 H 个观测值 o_t−H+1:t 和语言指令 l 输出动作 a_t ∼ π_θ(a_t | o_t−H+1:t, l),构建轨迹 τ = (o_0, a_0, . . .)。
监督微调 (SFT)。SFT 从专家收集的演示数据集 D_T = {(τ(i), l(i))} 中学习,其中每条轨迹为 τ(i) = (o(i)_0,a(i)_0,…,o(i)_K_i-1, a(i)_K_i-1),N 为轨迹总数。
强化学习微调。强化学习微调通过与环境直接交互来最大化标量奖励或偏好信号。通过奖励,它可以通常使用优势估计器 Aπ_t 通过策略梯度替代来最小化长度 M 的 episode 负折扣回报。对于偏好,诸如直接偏好优化 (DPO) (Rafailov,2023) 之类的方法,使用成对/排序反馈来优化 π_θ 以获得首选轨迹。
研究基于 OpenVLA (Kim,2024),如图所示,这是一个开源模型,通过将 SigLIP (Zhai,2023) 和 DINOv2 (Oquab,2023) 的融合视觉编码器与基于 Prismatic VLM (Karamcheti,2024) 构建的 Llama-2 7B 语言主干 (Touvron,2023) 配对,实现了最佳性能。在每个时间步,策略接收一个 RGB 图像 o_t 和一个指令 l,即历史长度 H = 1。图像被嵌入到视觉 tokens 中,指令使用 Llama 2 的标记器进行token化,并将生成的 token 序列输入到因果 transformer 解码器。OpenVLA 遵循 RT-2 离散化方案(Brohan,2023a):连续命令 a_t 中的每个标量都映射到 256 个 bin 中的一个,这些 bin 将训练集中其第 1 百分位数和第 99 百分位数之间的范围均匀划分,从而生成一个动作 token 向量 u_t ∈ {0, …, 255}d_a。这些动作 tokens 会覆盖 Llama-2 词汇表中 256 个最少使用的tokens,因此语言模型可以直接生成它们。然后使用通常的下一个 token 交叉熵目标对网络进行训练,并且仅根据预测的动作 tokens 计算交叉熵损失。

本文考虑三种具有代表性的强化学习算法:PPO (Schulman et al., 2017)、GRPO (Shao et al., 2024) 和 DPO (Rafailov et al., 2023; Zhang et al., 2024b)。所有模型均使用低秩自适应 (LoRA) (Hu et al., 2022) 进行微调,秩 = 32。
• PPO 执行在线策略更新,利用裁剪的重要性比和广义优势估计 (GAE) 从新收集的展开数据中计算策略梯度。Hu et al., 2025 的最新研究 Open-Reasoner-Zero (ORZ) 表明,在微调大模型时,禁用 广义优势估计 (GAE),即设置 γ = 1 和 λ = 1,可以提升性能。因此,在实验中评估标准算法 (PPO) 和此变型 (PPO-ORZ)。
• GRPO 使用一组样本估计基线,从而无需显式估计价值即可直接计算优势。虽然自然语言和机器人多步 MDP 任务之间存在差异,但还包括一个修改版 GRPO(s),其中采样的一组轨迹从相同的初始状态开始,正如 GRPO 论文 (Shao et al., 2024) 所建议的那样。在这两种设置中,都将从所有并行环境中收集的一批轨迹作为一个组用于一个任务情节。
• DPO 利用带有成对偏好注释的离线数据集。然而,在机器人任务中,从相同的初始状态获得对比轨迹是困难的。遵循 (Zhang et al., 2024b),从奖励信号中推断轨迹级偏好。为了确保公平比较,仅采用基于阶段的稀疏奖励。 而不是像 (Zhang et al., 2024b) 的原始实现中那样采用更丰富的奖励方案。
这些 VLA 微调算法如图 a 所示:

评估拾取放置任务的性能,结果如上图 b 所示,每个实验都使用两个不同的随机种子进行。研究结果表明,PPO 的表现始终优于 GRPO。作者将其归因于自然语言任务和机器人假设,在机器人任务的 POMDP 中,每个动作都会以非平稳的方式顺序改变环境状态,这可能会破坏 GRPO 的优势估计。此外,PPO 的性能优于 DPO。假设这是由于稀疏的奖励结构导致难以区分不同轨迹的质量,以及离线数据集和交互式执行之间的显著分布差异 (Prudencio et al., 2023)。
采用几个关键的设计选择,以使 PPO 能够有效地与 OpenVLA 协同工作。基于这些设计,主要实验需要在单个 NVIDIA A100 GPU 上进行大约 42 小时才能收敛。以下用两个不同的随机种子进行每个实验。
共享的 Actor-Critic 主干网络。由于 PPO 以及大多数现代强化学习方法都使用 Actor-Critic 公式(Konda & Tsitsiklis,1999),将预训练的 VLA 策略视为 Actor,并附加一个轻量级的 Critic 来估计状态值 V(s)。为了保持架构紧凑,Actor 和 Critic 共享整个 Transformer 主干网络;一个三层 MLP 状态值头(如图 a 所示)获取由最终 Transformer 模块(Vaswani,2017)在第一个动作 token 位置生成的隐藏向量 h0,并将其回归为标量值。为了验证其有效性,评估几种 Critics 设计。将第一个动作 token 嵌入 h0 馈送到状态值头可获得最高且最稳定的回报,优于最后一个 token 输入 hn 及其串联 [h0, …, hn](如图 b 所示)。使用自带 Transformer 主干网的 critic 获得类似的回报,但训练速度慢 35%,且 VRAM 消耗增加 83%(81.3 GB vs. 44.4 GB)。这些结果证实,与 h0 共享主干网是最高效的选择。

VLA 预热。用在 OXE 数据集 (Collaboration et al., 2023) 上预训练的官方 OpenVLA 检查点 (Kim et al., 2024) 运行所有实验。由于此检查点在基准测试中表现不佳,用 Octo-Small(Team et al., 2024)收集的 140 条演示轨迹和一个运动规划器对其进行预热。如下图 a 所示,预热模型以大约减少 50% 的环境步骤达到收敛,同时在交互充分的情况下,两种初始化方法均获得相当的渐近收益。除非另有说明,所有后续实验均使用预热后的 OpenVLA 模型进行初始化。

最小 PPO 迭代次数。更新-与-数据比率,是高效微调的关键因素。在 PPO 中,此比率由迭代次数超参设置,该参数指定每个批次接收的梯度传递次数。上图 b 和图 c 表明,将 PPO 迭代次数增加到 1 次以上不会带来收益或样本效率的提升,反而会几乎线性地延长挂钟时间。因此,在所有剩余的实验中固定 epoch = 1,在不牺牲性能的情况下实现最快的训练。
为了深入探究 VLA 的泛化能力,重点研究一个典型的拾取放置任务 (Kim et al., 2025; Li et al., 2024a),其中智体被指示将桌子上的物体放入容器中。受前期研究 (Fan et al., 2025; Stone et al., 2023) 和“视觉-语言-动作(VLA)”模型概念的启发,定义三个泛化维度:视觉、语义(语言)和执行(动作)。
• 视觉:同时考虑前景(动态纹理)和背景(未见表格)的变化,以及图像级动态噪声,这些噪声的强度可强可弱。
• 语义:考虑物体、容器和指令短语中未见的变化。此外,设计新的任务,要求使用见过或未见过的物体集,从两个物体中拾取一个(多物体)。还设计一个带有干扰容器的任务,以及一个需要将物体放置在两个未见容器中的一个的任务(多容器)。
• 执行:研究物体和容器初始位置的变化,以及机器人初始姿态的变化。此外,还引入一个新场景,其中物体的位置在任务执行过程中会发生变化(中期物体重定位)。
为了探索泛化能力,在训练过程中沿着三个轴随机化每个任务:视觉(16 个表格)、语义(16 个物体)和执行(物体和容器姿态的扰动)。在测试时,保留至少一个因素不包含在分布中,引入 9 个新物体、16 个未见过的容器、5 个新桌子环境和 16 个干扰纹理。资源取自 Objaverse(Deitke,2023)和其他公共来源;额外的桌子外观则使用 Stable Diffusion(Rombach,2022)和 ControlNet(Zhang,2023a)合成,以确保在不改变桌子整体姿态的情况下实现表面变化。
基于这些资源,任务在 ManiSkill(Tao,2024)中运行,该任务配备 8 自由度 WidowX-250S 机械臂。在每一步中,智体都会观察 640 × 480 RGB 帧和自然语言指令,并输出笛卡尔末端执行器增量和二进制夹持器信号。奖励是稀疏的:抓取并持续握住正确物体可获得 0.1 分,成功放置物体可获得 1.0 分。对于监督微调,用 MPLib 运动规划器 (Guo et al., 2024) 收集演示轨迹,并使用 LoRA (Hu et al., 2022) 进行微调。
继 Lin et al. (2025) 的研究之后,研究监督微调 (SFT) 如何随演示次数的增加而扩展。在包含数百到 6.4 万条专家轨迹(约 126 万个变换)的数据集上训练 OpenVLA 直至收敛,并报告分布内三个随机种子以及未见过的物体/桌子的平均得分(如图 a 和 b 所示)。在两种设置下,性能在轨迹数量约为 1.6 万条时达到稳定状态,因此采用 1.6 万条轨迹的 SFT 检查点作为比较强化学习微调方法的基准。

基于前述分析,在上图 c 和 d 中绘制强化学习 (RL) 训练期间针对训练分布和 OOD 目标/桌子划分的成功率,以及不同数据尺度下的 SFT 得分。在 OOD 任务上,大约 0.4 M 个环境步骤后,强化学习 (RL) 超越了最强的 SFT 检查点 (SFT-16k)。在收敛阶段,其在训练环境中的表现与 SFT-16k 相当,在未见过的目标和桌子上的表现则高出 42.6%,这表明强化学习不仅提升训练分布下的策略性能,而且还提供显著增强的泛化能力。
进一步评估收敛后的强化学习 (RL) 策略和表现最佳的 SFT 策略(SFT-16k,简称 SFT)在 OOD 任务上的泛化性能,如图所示。

其报告三个随机种子的平均成功率和平均性能下降情况。相对性能下降的计算公式为 P = (OOD−IND)/IND。结果表明,RL 在视觉任务中的表现与 SFT 相当,在语义任务中明显更胜一筹,在执行任务中更是大幅领先。
对于视觉任务,假设 RL 和 SFT 训练均无法在施加的视觉随机性(即随机训练表)之外实现视觉鲁棒性,因此两种方法的性能相似。在语义任务中,无论是在单个还是多个目标场景中,面对 OOD 目标时,RL 的表现都明显优于 SFT。假设通过反复试验,RL 能够以较少依赖目标类型的方式学习“抓取”技能,从而提高泛化能力。对于执行任务,RL 在所有三个评估场景中均优于 SFT。
为了探究两种方法之间的定性差异,将策略在四个代表性任务上的部署可视化(如图所示)。在视觉/动态噪声(强)测试中,SFT 智体在抓取物体后立即反复放下物体,这表明严重的视觉干扰阻碍了它定位容器,而强化学习智体则完成了放置。

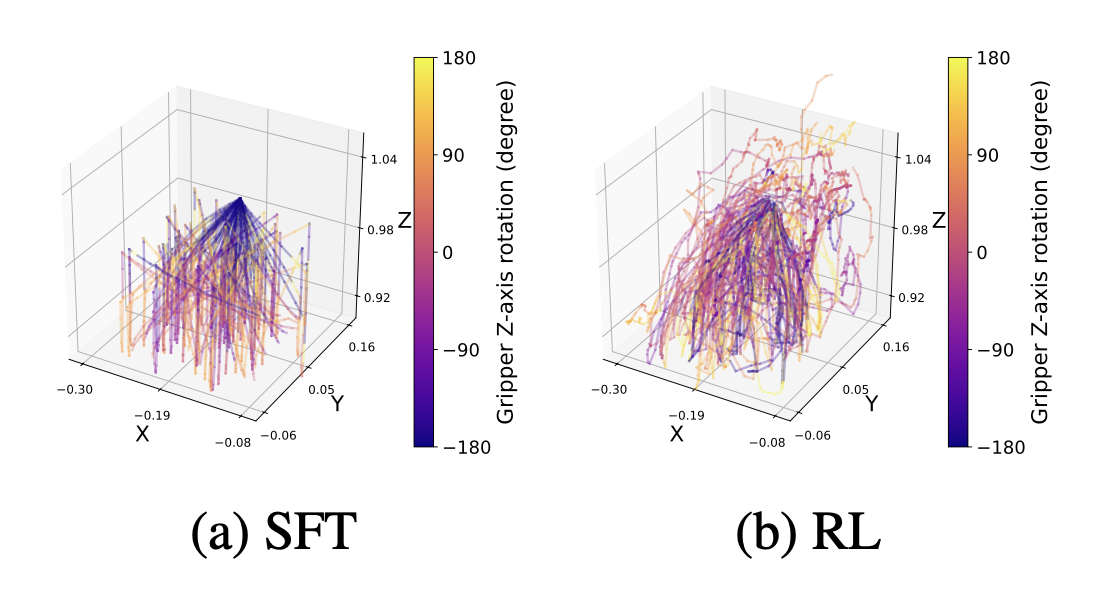
在语义测试中,对于一个未见物体,SFT 不断尝试抓取它已经握住的物体并停滞不前,而强化学习智体则将其拿起并完成任务。这可能归因于强化学习在训练过程中丰富的试错经验,使其能够在与未见物体交互时进行更精细的控制。在两次执行测试中,RL 还学会从抓取失败和场景中物体移动中恢复,而 SFT 则能够克服位置误差,这可能是因为此类情况从未出现在演示数据中。训练期间遇到的轨迹分布(如图所示)反映了这一差距:RL 轨迹覆盖的工作空间更广,末端执行器方向范围更丰富,而 SFT 的展开则沿着数据集中存在的运动规划器路径聚集。这种更广泛的覆盖范围似乎是 RL 在执行任务中表现出色泛化能力的关键。
下一篇:ROS2框架以及核心模块






 关注微信
关注微信