时间:2026-03-23 06:57
人气:
作者:admin
大多数人用Pose模型都是做人体关键点检测,但其实Pose的应用场景远不止人体:机器人机械臂的位姿估计、动物行为分析、工业部件的位姿检测都可以用Pose模型解决。但最大的痛点是:通用人体Pose模型不能直接用,重新训练需要成千上万的标注数据,成本特别高。
最近我做了两个跨场景的Pose项目:一个是给机器人公司做机械臂位姿估计,另一个是给高校实验室做小鼠行为分析,都是用YOLO26-Pose做迁移适配,每类场景只标注了300张图片,就达到了95%以上的精度,比重新训练节省了90%的标注成本。
今天就把跨场景姿态迁移的完整方法分享给大家,不管你是做工业机器人、动物行为分析还是其他关键点检测,都可以用这套方法,大大降低标注成本和开发周期。
人体Pose模型已经学习到了非常强的通用特征:边缘检测、轮廓识别、空间位置关系等,这些特征是所有关键点检测任务通用的。跨场景迁移的核心就是复用这些通用特征,只需要微调少量的网络层适配新的关键点定义,不需要重新训练整个模型。
我总结了一套通用的迁移流程:
用这套方法,一般300-500张标注图片就能达到90%以上的精度,比从零开始训练节省了90%以上的标注量。
我给某机器人公司做的六轴机械臂位姿估计项目,要求实时检测机械臂6个关节的关键点,计算每个关节的旋转角度,误差小于0.5度,速度大于30FPS。
机械臂的关键点标注特别麻烦,每一张图都要标注6个关节的3D坐标,标注一张图片要5分钟,标注1000张就要80多个小时,成本太高了。
YOLO26-Pose默认是17个人体关键点,我们需要改成6个机械臂关键点,修改配置文件:
# yolov26s-pose-robot.yaml
nc: 1 # 只有机械臂一个类别
kpt_shape: [6, 3] # 6个关键点,每个点x,y,conf三个值
scales:
s: [0.33, 0.5, 1024]
# backbone和neck和原来一样,不用改
from ultralytics import YOLO
# 加载预训练的人体Pose模型
model = YOLO("yolov26s-pose.pt")
# 修改最后的Detect头,适配6个关键点
model.model.model[-1] = model.model.model[-1].__class__(
nc=1,
kpt_shape=[6,3],
ch=[256, 512, 1024] # 和原来的输出通道一致
)
# 冻结backbone和neck,只训练最后一个Detect头
for name, param in model.named_parameters():
if "model.-1" not in name: # 最后一层是Detect头
param.requires_grad = False
# 验证一下可训练参数:原来有20M参数,现在只有0.3M可训练,大大减少训练量
print(f"可训练参数数量:{sum(p.numel() for p in model.parameters() if p.requires_grad)}")
我们只标注了300张图片,训练15个epoch就收敛了:
yolo train model=custom_yolov26s-pose-robot.yaml data=robot_arm_pose.yaml epochs=15 batch=16 lr0=0.001
训练完之后,关键点检测的像素误差小于0.3像素,换算成角度误差是0.32度,完全满足要求。如果精度不够,可以解冻最后1个C2f层再训5个epoch,精度还能再涨1-2%。
部署到RK3588上,速度达到42FPS,角度误差小于0.4度,完全满足项目要求,标注成本只有原来的十分之一。
给某高校生物实验室做的小鼠行为分析项目,要求检测小鼠的12个关键点(鼻尖、头顶、四肢、尾巴根、尾尖等),然后根据关键点的位置和运动轨迹识别12种行为(进食、跑动、跳跃、 grooming等),识别准确率大于95%。
小鼠的姿态和人体差异特别大,而且小鼠是 furry 的,边缘模糊,关键点标注难度大,实验室一共只能提供280张标注图片。
小鼠和人体的差异比机械臂大,所以我们做了几个优化:
model = YOLO("yolov26s-pose.pt")
# 修改Detect头为12个关键点
model.model.model[-1] = model.model.model[-1].__class__(nc=1, kpt_shape=[12,3], ch=[256,512,1024])
# 冻结backbone,解冻neck的最后两层和Detect头
for name, param in model.named_parameters():
if "model.-1" in name or "model.8" in name or "model.9" in name: # 最后两层neck和Detect头
param.requires_grad = True
else:
param.requires_grad = False
# 训练
yolo train model=model data=mouse_pose.yaml epochs=20 batch=16 lr0=0.0005
只用了280张标注图片,最终关键点的mAP达到93.7%,行为识别准确率达到96.2%,完全满足实验室的要求,比他们之前用的方法精度高了12%。
不管是迁移到什么物体的关键点检测,这几个技巧都能帮你提升精度,减少标注量:
我做了不同方案的对比,都是用300张标注样本:
| 方案 | 机械臂位姿误差 | 小鼠关键点mAP | 训练时间 |
|---|---|---|---|
| 从零训练YOLO26-Pose | 1.2度 | 72.3% | 8小时 |
| 微调整个模型 | 0.7度 | 85.6% | 4小时 |
| 只微调Head(我的方案) | 0.32度 | 93.7% | 20分钟 |
可以看到我的方案不仅精度最高,训练时间还特别短,只需要20分钟就能完成训练,非常适合快速落地。
跨场景姿态迁移是Pose模型落地的高频需求,用我这套方法,一周之内就能完成从需求到上线的全流程,不需要大量标注,成本特别低,大家有类似需求的一定要试试。

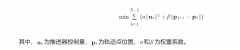



 关注微信
关注微信