时间:2026-03-16 19:10
人气:
作者:admin
面向正在开发和评估用于自动驾驶场景(特别是处理罕见的长尾事件)的 VLA 模型
https://www.modelscope.cn/models/nv-community/Alpamayo-R1-10B
GitHub: https://github.com/NVlabs/alpamayo
chrome-extension://efaidnbmnnnibpcajpcglclefindmkaj/file:///C:/Users/admin/Desktop/25a54ecc-762e-417a-b93a-563dfb3e7b01.pdf
基于 Cosmos-Reason 的 VLA 模型,并采用基于扩散模型的轨迹解码器。
本模型基于以下技术开发: Cosmos-Reason(VLM 主干网络)配合基于扩散模型的动作解码器
输入类型: 图像/视频、文本、自车运动历史(Egomotion History)
输入格式:
(x, y, z), R_rot输入参数:
其他与输入相关的属性: 多摄像头图像(4 个摄像头:前广角、前长焦、左交叉、右交叉),以 10Hz 频率采集,包含 0.4 秒历史窗口(每个摄像头 4 帧),图像分辨率为 1080x1920 像素(处理器会将其下采样至 320x576 像素)。文本输入包括用户指令。图像和自车运动历史(10Hz 下的 16 个路径点)还需附带相应的时间戳。 请注意,该模型主要在此设定下进行训练,且仅在此设定下经过测试。
输出类型: 文本、轨迹
输出格式:
(x, y, z), R_rot输出参数:
其他与输出相关的属性: 输出未来 6.4 秒的轨迹(10Hz 下的 64 个路径点),位置 (x, y, z) 和旋转矩阵 R_rot 均以自车坐标系表示。 在内部,轨迹以一系列动态动作(加速度和曲率)序列表示,遵循鸟瞰图(BEV)空间中的单轮车模型。 文本推理轨迹长度可变,用于描述驾驶决策及其因果因素。
我们的 AI 模型专为在 NVIDIA GPU 加速系统上运行而设计和/或优化。通过利用 NVIDIA 的硬件(例如 GPU 核心)和软件框架(例如 CUDA 库),相比纯 CPU 方案,该模型可实现更快的训练和推理速度。
运行时引擎:
Python(最低版本:3.12.x)
PyTorch(最低版本:2.8)
Hugging Face Transformers(最低版本:4.57.1)
DeepSpeed(最低版本:0.17.4)
详见:pyproject.toml
安装uv后,运行uv sync --active,自动读取pyproject.toml并进行安装
[project]
name = "alpamayo_r1"
version = "0.1.0"
requires-python = "==3.12.*"
dependencies = [
"accelerate>=1.12.0",
"av>=16.0.1",
"einops>=0.8.1",
"hydra-colorlog>=1.2.0",
"hydra-core>=1.3.2",
"pandas>=2.3.3",
"physical_ai_av>=0.1.0",
"pillow>=12.0.0",
"torch==2.8.0",
"torchvision>=0.23.0",
"transformers==4.57.1",
"flash-attn>=2.8.3",
]
[build-system]
requires = ["uv_build>=0.9.7,<0.10.0"]
build-backend = "uv_build"
[dependency-groups]
dev = [
"matplotlib>=3.10.7",
"mediapy>=1.2.4",
"ipykernel>=6.29.3",
"ipywidgets>=8.1.8",
]
[tool.uv]
no-build-isolation-package = ["flash-attn"]
[tool.ruff]
line-length = 100
支持的硬件微架构兼容性:
首选/支持的操作系统:
将基础模型和微调模型集成到 AI 系统中,需要使用特定用例的数据进行额外测试,以确保安全有效的部署。根据 V 模型方法论,在部署前,必须在单元级和系统级进行迭代测试与验证,以降低风险、满足技术和功能需求,并确保符合安全与伦理标准。
Alpamayo 1 的训练数据混合了因果链(CoC)推理轨迹、Cosmos-Reason 物理 AI 数据集以及 NVIDIA 内部专有的自动驾驶数据。
数据模态:
图像训练数据规模: 超过 10 亿张图像(来自 80,000 小时的多摄像头驾驶数据)
文本训练数据规模: 少于 10 亿个 token(70 万条 CoC 推理轨迹加上 Cosmos-Reason 训练数据)
视频训练数据规模: 10,000 至 100 万小时(80,000 小时)
非音频、图像、文本训练数据规模: 轨迹数据:以 10Hz 采样率采集的 80,000 小时数据
各数据集的数据采集方法: 混合方式:自动/传感器(摄像头和车辆传感器)、合成数据(VLM 生成的推理)
各数据集的标注方法: 混合方式:人工(结构化 CoC 标注)、自动化(基于 VLM 的自动标注)、自动/传感器(轨迹和自运动)
特性: 该数据集包含 80,000 小时的多摄像头驾驶视频,附带相应的自运动和轨迹标注。
其中包括 70 万条因果链(Chain-of-Causation, CoC)推理轨迹,提供基于决策、因果关联的驾驶行为解释。
内容包括来自车辆传感器(摄像头、IMU 和 GPS)的机器生成数据以及合成推理轨迹。
CoC 标注使用英语,并采用结构化格式,将驾驶决策与因果因素关联起来。
传感器包括 RGB 摄像头(每辆车 2–6 个)、惯性测量单元(IMU)和 GPS。
链接: 专有的自动驾驶测试数据集、闭环仿真、实车道路测试。
各数据集的数据采集方法: 混合方式:自动/传感器(真实世界驾驶数据)、合成数据(仿真场景)
各数据集的标注方法: 混合方式:自动/传感器、人工(真值验证)
特性: 该数据集涵盖多摄像头驾驶场景,特别关注罕见的长尾事件。包括复杂交叉路口、加塞、行人交互以及恶劣天气条件等具有挑战性的案例。数据由 RGB 摄像头和车辆传感器采集。
链接: 同测试数据集。
各数据集的数据采集方法: 混合方式:自动/传感器(真实世界驾驶数据)、合成数据(仿真场景)
各数据集的标注方法: 混合方式:自动/传感器、人工(真值验证)
特性: 评估重点在于罕见的长尾场景,包括复杂交叉路口、行人过街、车辆加塞,以及具有挑战性的天气和光照条件。多摄像头传感器数据由 RGB 摄像头采集。
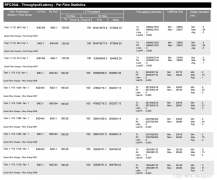
定量评估基准:
加速引擎: PyTorch、Hugging Face Transformers
测试硬件:
有关模型推理的脚本,请参阅官方的 代码仓库。


 关注微信
关注微信