时间:2026-03-17 10:38
人气:
作者:admin
原标题:Talk2Event: Grounded Understanding ofDynamic Scenes from Event Cameras

事件相机以微秒级精度记录亮度变化,具备抗模糊、低功耗、高动态范围等优势,适用于动态场景感知。然而,事件数据与自然语言的结合尚属空白,限制了其在多模态理解中的应用。同时,传统基于 RGB 图像 / 视频的视觉定位方法在高速运动、光照剧变等场景下表现不佳,且现有数据集多为静态场景或密集帧数据,无法适配事件相机的异步稀疏信号特性。本文提出 Talk2Event 任务与数据集,首次实现基于语言的事件数据视觉定位,同时配套设计 EventRefer 属性感知框架,推动事件视觉与语言融合发展。

Talk2Event 所体现的事件 + RGB 多模态设定,与事件视觉硬件在工程侧的演进方向高度一致。在实际应用中,单一事件相机已难以同时满足高速动态感知与稳定语义理解的需求,融合型视觉系统逐渐成为主流选择。
灵光 1 号 RGB + EVS 视觉融合相机 正是在这一工程背景下形成的产品方案:在同一系统中同步获取 RGB 图像与微秒级事件流,既保留事件相机在高速与高动态范围场景下的优势,又补充了可靠的纹理与语义信息,为事件视觉相关的多模态研究与落地应用提供了更稳定的硬件基础。

任务定义:输入事件流与自然语言描述,输出目标对象的边界框。
数据表示:将异步事件流离散为 4D 体素张量(维度含事件极性信息),保留时间与极性特征;同步帧图像(RGB 三通道)用于多模态融合,实现跨模态互补。
属性建模:每条语言描述包含四类属性 —— 外观(如“白色轿车”)、状态(如“缓慢移动”)、与观察者关系(如“前方”)、与其他对象关系(如“公交车旁”),支持精细语义解析与组合推理。
核心模型:提出 EventRefer 框架,通过正向词匹配定位属性关键词、事件 - 属性混合专家模块动态融合有效属性、多属性融合保证定位一致性,提升跨模态对齐精度。

首次提出事件视觉中的语言驱动定位任务,填补事件数据与自然语言结合的领域空白。
构建 Talk2Event 数据集,具备结构化属性标注与多模态监督,质量与规模领先。
提供三种评估模式:仅事件、仅图像、事件 + 图像,支持多模态对比研究。
设计 EventRefer 属性感知框架,在三种评估模式下均实现 SOTA 性能,为任务提供有效解决方案。
来源:基于 DSEC 真实驾驶数据集构建,贴近自动驾驶等实际应用场景。
规模:包含 5567 个场景、13458 个对象、30690 条经验证的语言描述,训练集 4433 个场景、测试集 1134 个场景。
标注:由 Qwen2-VL 结合目标前后 200 毫秒双帧上下文生成 3 条差异化描述,经人工审核验证;平均长度达 34.1 词,远超现有数据集;每条语句附带四类属性标签,标注流程含自动解析 + 人工验证。
质量控制:通过可见性过滤(移除遮挡对象)、冗余过滤(保证描述多样性)、属性验证(每条描述至少含 1 类属性),确保数据有效性。

与现有基准对比:Talk2Event 是唯一支持动态场景、结构化属性标注与事件数据的视觉定位数据集,优势显著。
语言表达覆盖广泛,具备丰富的动作、空间与关系词汇,描述细致且贴合场景。
提供多样化样本,涵盖车辆、行人、骑行者等 7 类对象,场景包含 1-9 + 个对象的稀疏与密集情况,适用于多任务研究与复杂场景适配。
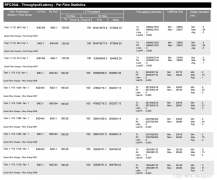
模型性能:EventRefer 在三种模态下均超越现有 SOTA 方法,融合模式平均准确率达 61.82%,尤其在动态目标定位上优势突出。
--END--
声明:本文为论文解读与技术讨论性质文章。文中涉及的工程方案与产品信息仅作为行业实践示例,不构成对论文方法、性能或适用性的评价与背书。
论文原文:https://pan.baidu.com/s/1anBjyzfaADp-uETIW2jv6g 提取码: f3ea
数据集:https://talk2event.github.io/


 关注微信
关注微信